Introduction
Le traçage permet d'instrumenter un noyau pour capturer les événements bas niveau (allocation mémoire, changement de contexte, réception d'un paquet réseau, ...,etc).
Le traçage a fait l'objet des deux articles précédents, nous avons présenté des outils tels que Ftrace, Perf et Lttng.
Dans cet article, nous allons décrire eBPF, le traceur le plus performant sous Linux.
Quelques généralités sur eBPF
C'est quoi eBPF ?
eBPF est le nouveau traceur du noyau Linux disponible depuis la version 3.15.
C'est quoi un traceur?
Nous avons réalisé une animation pour appréhender la notion de trace mais également pour la différencier de la notion de profilage : https://jugurthab.github.io/debug_linux_kernel/linux-tracers-utility.html
BPF (Berkeley Packet Filter) est la célèbre machine virtuelle (exécutée dans le noyau) utilisée par tcpdump.
eBPF (Extended Berkeley Packet Filter) est l'extension de BPF. Cependant eBPF fait beaucoup plus que manipuler des paquets, il peut servir comme un outil d'observabilité (afficher l'activité du système), mitigation DDOS, détection d’intrusion, ...,etc (voir l'image ci-dessous).
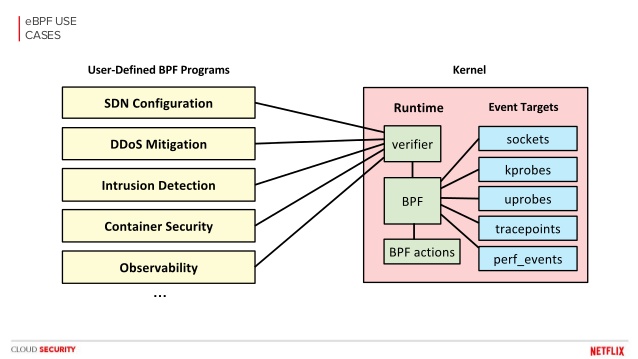
Pourquoi choisir eBPF
Les traceurs classiques sous Linux (Ftrace, Perf, LTTng) ne sont pas reprogrammables, l'utilisateur se contente d'utiliser les fonctions qu'ils mettent à sa disposition.
Voici les principales différences existantes entre eBPF et les autres traceurs :
- eBPF est reprogrammable, on peut lui faire exécuter toutes les tâches qu'on peut imaginer (mais il existe des règles à respecter, nous en parlons dans la suite),
- La capture des événements se fait en temps réel (la trace n'est pas sauvegardée dans un fichier comme Ftrace ou Perf),
- Les scripts eBPF engendrent peu d’impacts sur le système en termes d'empreinte mémoire et temps de latence,
- Les codes eBPF ne peuvent pas crasher un système car le code défini par l'utilisateur est exécuté en sandbox dans le noyau (source : https://lkml.org/lkml/2015/4/14/232).
Bcc, le front-end de eBPF
L'accès à eBPF est complexe car il faut programmer un comportement dans un langage qui s'apparente à du C. Bcc est un outil permettant de simplifier l'accès à eBPF.
Bcc (BPF Compiler Collection) est un toolkit (voir son logo dans l'image ci-dessous) qui permet de créer facilement des programmes eBPF (qui sont normalement codés dans une variante du langage C).

Bcc permet d'instrumenter le noyau avec un programme C et de récupérer les résultats en Python (ou même lua ou golang).
Nous allons voir comment créer des scripts eBPF à l'aide de Bcc.
Le support de Bcc est déjà existant depuis Linux4.4; cependant, c'est à partir de la version 4.9 que l’intégralité des fonctionnalités de l'outil sont complètement incluses.
Compiler les sources de Bcc pour une distribution?
L'installation de Bcc sur différentes distributions Linux est expliquée sur le lien suivant:
https://github.com/iovisor/bcc/blob/master/INSTALL.md
Utiliser les scripts Bcc (solution sur étagère)
Les scripts inclus avec Bcc peuvent suffire à résoudre les tâches les plus communes. Les exemples sont bien illustrés sur la page : https://github.com/iovisor/bcc/blob/master/README.md.
Nous allons reprendre quelques exemples :
- examples/tracing/stacksnoop : affiche la trace inverse d'une fonction (nous avons choisi "handle_mm_fault" à titre d'exemple).
machine-Machine bcc-master # python ./examples/tracing/stacksnoop.py -v handle_mm_fault TIME(s) COMM PID CPU FUNCTION 0.000402927 python 4829 1 handle_mm_fault handle_mm_fault do_page_fault page_fault 0.061583996 python 4829 1 handle_mm_fault handle_mm_fault do_page_fault page_fault 0.061750889 python 4829 1 handle_mm_fault handle_mm_fault do_page_fault page_fault
La signification des colonnes est la suivante :
- TIME(s) : c'est le timestamp.
- COMM : Le programme qui a appelé la fonction.
- PID : PID du programme qui a appelé la fonction.
- CPU : CPU sur lequel la fonction a été exécutée.
- examples/tracing/task_switch.py : pour visualiser l'ordonnancement des tâches :
machine-Machine bcc-master # python ./examples/tracing/task_switch.py task_switch[ 4394-> 4395]=152 task_switch[ 3831-> 1638]=1 task_switch[ 2211-> 4473]=2 task_switch[ 1639-> 0]=3 task_switch[ 3703-> 3675]=1
Le format du résultat est le suivant :
task_switch[ PID_tache_precedente -> PID_tache_suivante] = nombre préemption tache précédente
- tools/cachestat : Pour obtenir les statistiques liées au cache :
machine-Machine bcc-master # python ./tools/cachestat.py 1 TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB 1 0 1 0 50 704 0 0 0 0 50 704 9 8 1 0 50 704 0 0 0 0 50 704 1 0 1 0 50 704 514 0 514 0 50 704 0 0 0 0 50 704 366 0 366 0 50 704 523 1 522 1 50 704 912 0 912 0 50 704 3180 0 3180 0 50 704 ^C 0 0 0 0 50 704 Detaching...
- tools/memleak : Pour détecter les fuites mémoire :
machine-Machine bcc-master # python ./tools/memleak.py Attaching to kernel allocators, Ctrl+C to quit. [15:13:06] Top 10 stacks with outstanding allocations: 480 bytes in 5 allocations from stack kmem_cache_alloc_node_trace+0x1af [kernel] alloc_vmap_area+0x8d [kernel] __get_vm_area_node+0xb4 [kernel] __vmalloc_node_range+0x73 [kernel] __vmalloc+0x4a [kernel] bpf_prog_alloc+0x35 [kernel] bpf_prog_load+0x138 [kernel] SyS_bpf+0x3e0 [kernel] entry_SYSCALL_64_fastpath+0x1e [kernel] 576 bytes in 6 allocations from stack kmem_cache_alloc_trace+0x143 [kernel] bpf_prog_alloc+0x87 [kernel] bpf_prog_load+0x138 [kernel] SyS_bpf+0x3e0 [kernel] entry_SYSCALL_64_fastpath+0x1e [kernel]
Important : dans le cas où memleak est appelé sans aucun autre paramètre, l’allocateur SLAB sera tracé.
- tools/hardirqs : Pour tracer les interruptions matérielles.
jugurtha-VirtualBox bcc-master # python ./tools/hardirqs.py Tracing hard irq event time... Hit Ctrl-C to end. ^C HARDIRQ TOTAL_usecs ata_piix 294 i8042 431 enp0s3 472 vboxguest 5452 ahci[0000:00:0d.0] 34840
Création de scripts eBPF avec Bcc
Mais avant ça, c'est quoi un tracepoint?
Un tracepoint (probe) est un marqueur qui est attaché à une fonction, il en existe 4 types; usdt, tracepoint, uprobe, kprobe :
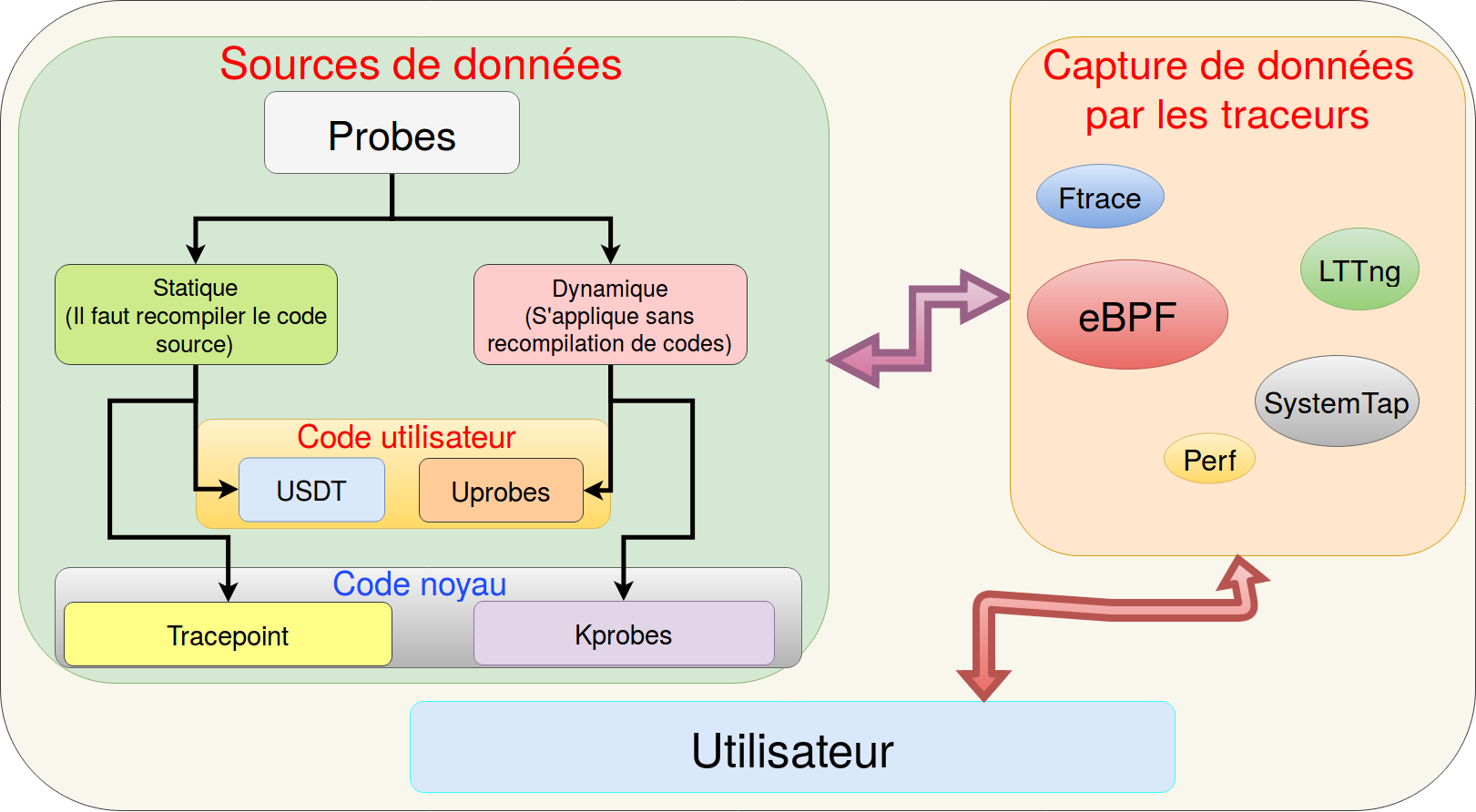
USDT et Tracepoint
Ce sont des marqueurs définis dans le code source de l'utilisateur (usdt) et du noyau (tracepoints) respectivement. Les fonctions printf et printk sont des exemples de marqueurs qui indiquent la progression du programme.
A retenir : La re-compilation de code est obligatoire (ce sont des marqueurs statiques).
Uprobe et Kprobe
Ce sont des marqueurs qui s’insèrent à chaud sur les applications utilisateur (uprobes) et le noyau (kprobe) respectivement.
A retenir : Il n'est pas nécessaire de recompiler le code dans ce cas.
Les scripts eBPF
Le langage le plus utilisé pour créer des scripts eBPF est Python (grâce à bcc). Par conséquent, nos scripts doivent être créés avec l'extension ".py".
Structure d'un script eBPF/bcc
Bcc utilise des langages conventionnels (contrairement à un traceur comme SystemTap), il suffit d'avoir des connaissances en C et en python. La structure d'un script eBPF est la suivante :
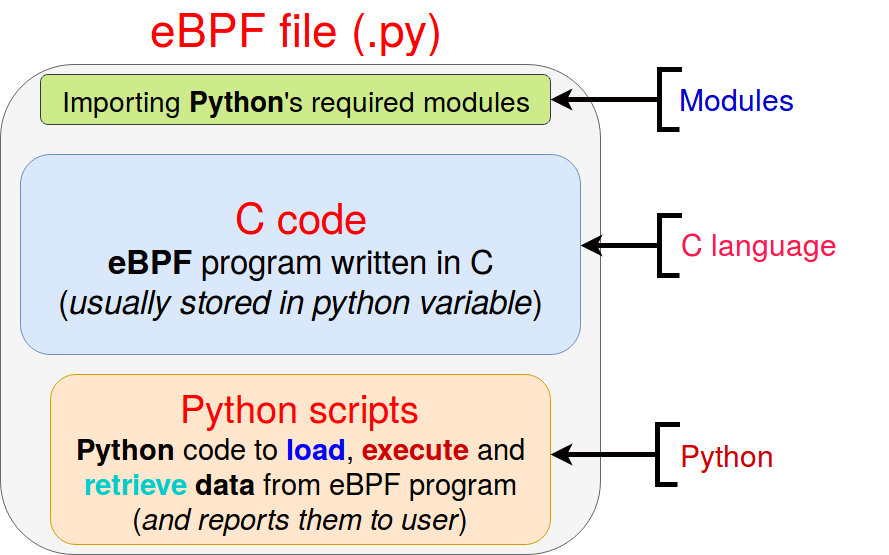
Bien gérer la capture des événements
La compréhension de cette section est obligatoire pour créer des scripts eBPF
eBPF permet de partager les données avec l'espace utilisateur grâce à 3 mécanismes différents :
- Le tampon PERF : eBPF recommande l'utilisation du tampon PERF (Perf Buffer). eBPF permet de capturer les événements, les enregistrer dans une structure C qui sera envoyée vers le tampon Perf (avec la fonction perf_submit). Les données doivent être récupérées en espace utilisateur (avec la fonction perf_buffer_poll()), puis il faut parser leur contenu avec la fonction (open_perf_buffer) et copier le contenu de la structure C vers une structure python (avec la fonction cast) pour pouvoir les afficher.
Limitation : La structure C sera effacée à chaque itération (un programme eBPF s'exécute à l'infini) du programme eBPF, donc cela ne permet pas d'avoir un historique pour calculer les latences ou faire un simple compteur. - Les structures Maps : sont des structures de données eBPF plus complexes que les structures C qui permettent d'avoir une persistance des données à chaque itération d'un programme eBPF. Cela nous permet de créer des statistiques (comme le nombre de paquets IP reçus, les différentes latences, ..., etc). Les Maps peuvent être envoyés à l'utilisateur par l’intermédiaire du fichier /sys/kernel/debug/tracing/trace_pipe, le tampon Perf ou lus directement (nous verrons cela plus tard).
- Le fichier /sys/kernel/debug/tracing/trace_pipe (pas recommandé) : Ce fichier peut être écrit par eBPF (avec la fonction bpf_trace_printk) et lu en espace utilisateur (avec les fonctions trace_print() ou trace_fields()).
Important : Plusieurs traceurs écrivent sur ce fichier, les données eBPF peuvent vite se mélanger et la lecture sera incohérente. Ce fichier est souvent réservé à des fins d'exemples et pour bien commencer eBPF.
Un exemple de script
Nous illustrons, ci-après, les différents moyens de partager les informations avec l'utilisateur; trace_pipe, le tampon PERF, maps.
Usage du fichier /sys/kernel/debug/tracing/trace_pipe
On peut rappeler, encore une fois, qu'un programme eBPF possède 3 parties (au minimum) :
- Partie 1 - Importation des modules : Importer les modules python (au moins le module bcc).
from bcc import BPF
- Partie 2 - Définir le programme eBPF : les étapes suivantes doivent être suivies :
- Choisir la fonction à tracer (nous allons illustrer avec "sys_mkdir")
- Indiquer le type de tracepoint à appliquer : kprobe, jprobe, usdt (dans notre cas, une kprobe).
- Coder la routine qui sera appelée lorsque la fonction à tracer s’exécutera (on va l'appeler par exemple direMerciPourCreationDossier). La routine doit définir aussi où les données capturées par eBPF seront redirigées.
N.B : Il est important de noter que ces étapes ne se font pas dans l'ordre indiqué.
Voici un exemple de code :
# Define eBPF program b = BPF(text = """ int direMerciPourCreationDossier(void *ctx){ bpf_trace_printk("SMILE dit : Merci pour le nouveau dossier\\n"); return 0; } """) # Attach a kprobe to the function sys_clone b.attach_kprobe(event="sys_mkdir", fn_name="direMerciPourCreationDossier")
Quelques explications s'imposent :
- La méthode attach_kprobe va insérer une kprobe dans la fonction "sys_mkdir" et va appeler la routine indiquée par fn_name lorsque la kprobe est déclenchée. Il faut noter que la kprobe est insérée au début de la fonction C (donc après le prologue).
- Le paramètre text définit le corps de la routine à appeler.
- La fonction BPF charge le programme dans la machine virtuelle eBPF.
- La fonction bpf_trace_printk écrit un message dans le fichier "/sys/kernel/debug/tracing/trace_pipe" (cette fonction doit être utilisée seulement à des fins éducatives, nous verrons, dans la suite, une façon plus pertinente pour partager les données avec l'utilisateur).
- void *ctx : registres de contexte BPF (on verra plus tard l'utilisation).
- Partie 3 - Récupérer les résultats : Il suffit de lire les traces et de les envoyer vers l'espace utilisateur.
b.trace_print()
Important : La fonction lit le contenu du fichier "/sys/kernel/debug/tracing/trace_pipe».
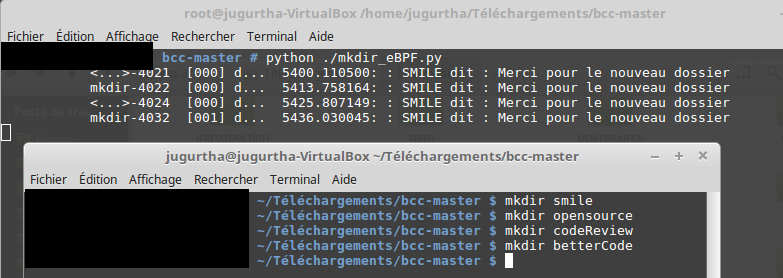
Voici, ci-dessous le code complet de notre script :
# mkdir_eBPF.py from bcc import BPF # Define eBPF program b = BPF(text = """ int direMerciPourCreationDossier(void *ctx){ bpf_trace_printk("SMILE dit : Merci pour le nouveau dossier\\n"); return 0; } """) # Attach a kprobe to the function sys_clone b.attach_kprobe(event="sys_mkdir", fn_name="direMerciPourCreationDossier") # Display trace results to end user b.trace_print()
Remarque : ne jamais utiliser d'accents même pour un commentaire du script eBPF (le script ne va pas compiler).
Mieux structurer le code
On peut encore modifier le code pour qu'il soit plus lisible :
- La routine qui doit être appelée peut être assignée à une variable python puis affectée au paramètre text.
programme = """ int direMerciPourCreationDossier(void *ctx){ bpf_trace_printk("SMILE dit : Merci pour le nouveau dossier"); // -- must always return 0 for every eBPF program -- return 0; } """
- Afficher un message à l'utilisateur pour confirmer le bon démarrage d'eBPF.
print("Pour stopper eBPF ..... Ctrl+C")
Voila un code beaucoup plus propre qui attache une kprobe à l'appel système "sys_mkdir", on y retrouve les modifications décrites ci-avant.
# ----------------- Part 1 - Import python libraries ---------------------- # At least BPF library must be imported from bcc import BPF # ----------------- End Part 1 - Importing libraries ---------------------- # ----------------- ------------------------------------------------------- # ------------------ Part 2 - Define eBPF program ------------------------- # ------------------------------------------------------------------------- # It is recommanded to store eBPF programs in a python variable programme = """ int direMerciPourCreationDossier(void *ctx){ bpf_trace_printk("SMILE dit : Merci pour le nouveau dossier"); // Remember to always return 0 return 0; } """ # Indicate which eBPF program to use b = BPF(text = programme) # Execute direMerciPourCreationDossier when sys_mkdir is detected (using Kprobe) b.attach_kprobe(event="sys_mkdir", fn_name="direMerciPourCreationDossier") # ------------------ End part 2 - eBPF program ---------------------------- # ------------------------------------------------ ------------------------ # ------------------ Part 3 - Report traces to user ----------------------- # ------------------------------------------------------------------------- print("Pour stopper eBPF ..... Ctrl+C") # ------------------- Reading traces and displaying them ------------------ b.trace_print() # ------------------ End part 3 - Report to user -------------------------- # -------------------------------------------------------------------------
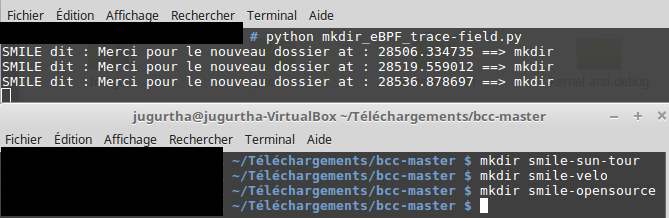
Nous allons exécuter le code comme indiqué dans la figure ci-dessous :
trace_fields : une variante de trace_print
trace_print() récupère tout le contenu du fichier "/sys/kernel/debug/tracing/trace_pipe" et l'affiche, trace_fields() peut parser le résultat pour que nous puissions avoir un affichage personnalisé. Le nouveau code sera le suivant :
# ----------------- Part 1 - Import python libraries ---------------------- # At least BPF library must be imported from bcc import BPF # ----------------- End Part 1 - Importing libraries ---------------------- # ----------------- ------------------------------------------------------- # ------------------ Part 2 - Define eBPF program ------------------------- # ------------------------------------------------------------------------- # It is recommanded to store eBPF programs in a python variable programme = """ int direMerciPourCreationDossier(void *ctx){ bpf_trace_printk("SMILE dit : Merci pour le nouveau dossier"); // Remember to always return 0 return 0; } """ # Indicate which eBPF program to use b = BPF(text = programme) # Execute direMerciPourCreationDossier when sys_mkdir is detected (using Kprobe) b.attach_kprobe(event="sys_mkdir", fn_name="direMerciPourCreationDossier") # ------------------ End part 2 - eBPF program ---------------------------- # ------------------------------------------------ ------------------------ # ------------------ Part 3 - Report traces to user ----------------------- # ------------------------------------------------------------------------- print("Pour stopper eBPF ..... Ctrl+C") # ------------------- Reading traces and displaying them ------------------ while 1: # b.trace_fields() parses traces and saves result into a tuple (task, pid, cpu, flags, ts, msg) = b.trace_fields() # Customize the display to user print("%s at : %f ==> %s " % (msg, ts, task)) # ------------------ End part 3 - Report to user -------------------------- # -------------------------------------------------------------------------
Il est important de noter que l'ordre des variables dans le tuple (task, pid, cpu, flags, ts, msg) ne peut pas être changé. Une fois le tuple créé, libre à nous d'afficher le résultat comme souhaité (voir l'image ci-dessous).
Usage du tampon PERF (BPF_PERF_OUTPUT)
L'idée globale est de créer une structure dans le programme eBPF (programme C) et de créer une structure équivalente en python (grâce au module ctypes) et refléter les données de la structure C sur cette dernière.
Nous allons continuer avec notre détecteur de création de dossier, et nous allons ajouter un timestamp du moment de la capture de l'événement. Voici les changements qui doivent être apportés :
Coté C :
# Variable "programme" to store eBPF code programme = """ // Structure data model to share with userspace struct timestamp_mkdir_class{ // field to store folders timestamp creation u64 timestamp_mkdir; }; // Create a channel in PERF BUFFER // We can call it events but can be named anything BPF_PERF_OUTPUT(events); int detect(struct pt_regs *ctx){ // Instantiate the structure and initialize it to zero struct timestamp_mkdir_class timestampMkdirInstance = {}; // bpf_ktime_get_ns() returns current time in nanoseconds timestampMkdirInstance.timestamp_mkdir = bpf_ktime_get_ns(); // Send the structure to PERF BUFFER (Channel events) events.perf_submit(ctx, ×tampMkdirInstance, sizeof(timestampMkdirInstance)); return 0; // always return 0 } """
Le code peut s'expliquer de la manière suivante :
- Déclaration de la structure timestamp_mkdir_class qui contiendra le timestamp.
- Déclaration du canal à utiliser avec le tampon Perf (dans notre cas, on a créé un canal qui s'appelle events).
- Utiliser la fonction bpf_ktime_get_ns() pour récupérer le temps courant en nanosecondes.
- Envoyer la structure vers le tampon Perf (avec la méthode perf_submit).
- struct pt_regs *ctx : récupère les registres de contexte eBPF car ils sont utilisés par la fonction perf_submit (généralement on n'utilise pas ces registres pour nous même).
Coté python
- Importation de modules : Le module ctypes permet de charger des bibliothèques (généralement des bibliothèques .so écrites en C) mais aussi de définir des structures.
from bcc import BPF import ctypes as ct
- Création de la structure équivalente en Python :
class Data(ct.Structure): _fields_ = [("timestamp_mkdir", ct.c_ulonglong)]
Nous avons créé une classe Python qui se nomme Data (mais vous pouvez la nommer comme vous voulez, Data est très utilisé dans les scripts officiels), qui va être le reflet de notre structure C «timestamp_mkdir_class». Par conséquent; le nombre, type et ordre des arguments doit correspondre pour les deux.
Il est préférable de garder les mêmes noms de champs (dans notre exemple "timestamp_mkdir »). Le type "ulonglong" est défini par la bibliothèque ctype comme le type Long. Pour trouver la correspondance des types entre les types classiques (int, float, boolean, ...,etc) et ceux définis par ctype, il faut regarder sur cette page : https://docs.python.org/2/library/ctypes.html#fundamental-data-types
- Changement de la partie affichage utilisateur : Formatage des données.
# afficher_evenement parses messages received from perf_buffer_poll def afficher_evenement(cpu, data, size): evenement = ct.cast(data, ct.POINTER(Data)).contents print("Nombre de mk_dir est %f", evenement.timestamp_mkdir) b["events"].open_perf_buffer(afficher_evenement) # print result to user while 1: # read messages from PERF BUFFER and send them to afficher_evenement b.perf_buffer_poll()
Le code doit être lu comme suit :
- Le tampon Perf est lu périodiquement par l'espace utilisateur avec "perf_buffer_poll()».
- Les données lues avec perf_buffer_poll() sont envoyées à la fonction open_perf_buffer qui va extraire et diviser l'information (cpu est le processeur sur lequel l'événement a été observé, data est la structure C et size est la taille de data).
- open_perf_buffer va appeler la fonction afficher_evenement (l'ordre des paramètres ne peut pas être modifié). Cependant, jusqu'a maintenant j'ai dit que les données étaient reflétées vers la structure Data (j'ai dit cela au début pour simplifier). En réalité, Data sert de modèle pour indiquer à python le format des données contenues dans la structure C (qui se trouve dans le paramètre data). Les données seront réellement copiées vers la variable "evenement" (en Python une variable peut stoker n'importe quel type). Enfin on peut afficher le résultat avec la fonction print ou même faire des traitements plus élaborés (comme visualiser les données sur un graphique, stockage sur une base de données, ..., etc).
Et enfin le code complet :
from bcc import BPF import ctypes as ct # prog will store the eBPF program prog = """ struct timestamp_mkdir_class{ u64 timestamp_mkdir; }; // Create a channel in PERF BUFFER BPF_PERF_OUTPUT(events); int detect(struct pt_regs *ctx){ struct timestamp_mkdir_class timestampMkdirInstance = {}; timestampMkdirInstance.timestamp_mkdir = bpf_ktime_get_ns(); events.perf_submit(ctx, ×tampMkdirInstance, sizeof(timestampMkdirInstance)); return 0; // always return 0 } """ # Loads eBPF program b = BPF(text=prog) # Attach kprobe to kernel function and sets detect routine as jprobe handler b.attach_kprobe(event="sys_mkdir", fn_name="detect") class Data(ct.Structure): _fields_ = [("timestamp_mkdir", ct.c_ulonglong)] # Show a message when eBPF starts print("Detection stated .... Ctrl-C to end") def afficher_evenement(cpu, data, size): evenement = ct.cast(data, ct.POINTER(Data)).contents print("Nombre de mk_dir est %f", evenement.timestamp_mkdir) b["events"].open_perf_buffer(afficher_evenement) # print result to user while 1: # read messages from PERF BUFFER b.perf_buffer_poll()
Et si nous devons transmettre plusieurs données vers l'espace utilisateur?
Il suffit de compléter la structure C, comme cela par exemple :
struct timestamp_mkdir_class{ u64 timestamp_mkdir; u32 pid_processus; };
Puis remplir la structure dans la routine (la fonction bpf_get_current_pid_tgid() retourne le PID) :
data.pid = bpf_get_current_pid_tgid();
Et un dernier changement pour notre structure Data (coté python):
class Data(ct.Structure): _fields_ = [("timestamp_mkdir", ct.c_ulonglong), ("pid_processus",ct.c_uint)]
Usage des maps
Les structures sont un moyen très puissant de faire passer les données capturées par eBPF vers l'espace utilisateur. Cependant, une structure ne sauvegarde pas son contenu car elle est créée à l'intérieur de la routine.
eBPF ne permet pas de créer des instances de structures à l'extérieur des routines. La raison est simple, il existe des types de structures plus complexes et plus adaptées pour sauvegarder les données; les Maps.
Les Maps vont permettre de créer des compteurs (comme compter le nombre de packets ip reçus), de sauvegarder les latences pour faire une moyenne.
Pour résumé les Maps vont servir à faire des statistiques.
Il existe plusieurs types de Maps, nous allons voir que la plus connue qui porte le nom de :BPF_HASH.
Voici un exemple d'utilisation ci-après :
from bcc import BPF # prog will store the eBPF C program prog = """ // Create Associative Arrays called compteur // If access index type is not specified, it defaults to u64 BPF_HASH(compteur); // equivalent to BPF_HASH(compteur, u64); int detect(void *ctx){ u64 index_compteur = 0; // index variable to access compteur elements u64 *compteur_pointeur;// to read content of element chosen with index_compteur u64 nouveauCompteur=1; // to update content of element chosen with index_compteur compteur_pointeur = compteur.lookup(&index_compteur); if(compteur_pointeur!=0){ nouveauCompteur = *compteur_pointeur + 1; bpf_trace_printk("Nombre de dossier(s) : %d\\n", nouveauCompteur); compteur.delete(&index_compteur); } compteur.update(&index_compteur, &nouveauCompteur); return 0; // always return 0 } """ # Loads eBPF program b = BPF(text=prog) # Attach kprobe to kernel function sys_mkdir and sets detect as kprobe handler b.attach_kprobe(event="sys_mkdir", fn_name="detect") # Show a message when eBPF starts print("Detection stated .... Ctrl-C to end") b.trace_print()
Essayons de détailler le code, nous allons voir seulement ce qu'il y a dans la variable "programme», le reste a déjà été abordé :
- BPF_HASH : sert à définir un tableau associatif. Dans notre cas, on l’appellera "compteur". On peut lui fournir le type de la clef comme paramètre secondaire (la clef sert comme index pour accéder aux éléments du tableau). A noter : le type de la clef peut être un entier, une chaîne de caractères ou même une structure (tout ce qui permet d'accéder d'une manière unique à un tableau).
- Manipuler le tableau : nous avons besoin de trois variables pour manipuler un tableau associatif (BPF_HASH).
- L'index (dans notre cas index_compteur) : permet d'accéder à un élément du tableau.
- Un pointeur (dans notre cas compteur_pointeur) : la fonction lookup renvoie un pointeur sur l’élément indiqué par l'index (dans notre cas index_compteur). Ce pointeur doit être récupéré pour pouvoir lire le contenu de l’élément.
- Une variable intermédiaire (dans notre cas nouveauCompteur) : eBPF ne permet pas de modifier directement le contenu de l’élément avec le pointeur (dans notre cas compteur_pointeur). Il est interdit d'écrire : *compteur_pointeur = valeur. La valeur de l'élément référencé par le pointeur doit être chargée dans une variable (dans notre cas nouveauCompteur), puis nous pouvons manipuler cette variable (dans notre exemple on incremente avec 1). La fonction update permet d'actualiser la valeur d'un élément d'un tableau associatif avec la valeur d'une variable intermédiaire.
- Vérifier si un pointeur est nul : eBPF nous oblige à vérifier si un pointeur est nul. Sans la ligne (if(compteur_pointeur!=0)), la compilation va échouer.
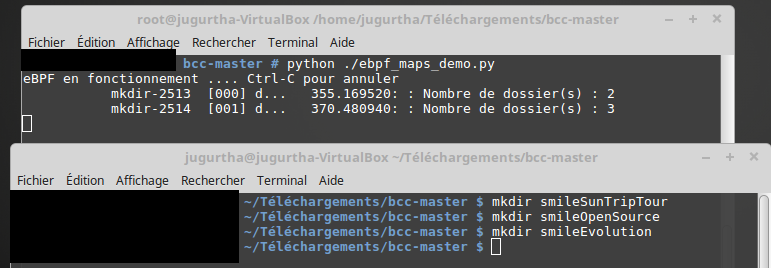
Comme vous pouvez le voir, la valeur compteur est envoyée vers le fichier "/sys/kernel/debug/tracing/trace_pipe" pour être lue par l'utilisateur.
Important : Le script n’incrémente pas le compteur pour le premier dossier créé, en effet, un élément du tableau associatif est créé avec la fonction update, donc, la condition (compteur_pointeur=NULL) est fausse durant la première itération du programme.
Les tracepoints
Jusqu'a présent, nous avons seulement considéré l'usage des kprobes mais on peut également utiliser des tracepoints.
Choisir un tracepoint à tracer avec eBPF
Un tracepoint ne peut pas être attaché pour chaque fonction du noyau, par conséquent, seulement quelques fonctions peuvent être tracées de la sorte.
La liste complète des tracepoints supportés se trouve dans le fichier : /sys/kernel/debug/tracing/events/
Pour notre exemple, nous choisissons de tracer l'événement writeback_dirty_page (/sys/kernel/debug/tracing/events/writeback/writeback_dirty_page).
Création du tracepoint
Créer un tracepoint est simple :
from bcc import BPF # prog will store the eBPF C program prog = """ // Enable the tracepoint TRACEPOINT_PROBE(writeback, writeback_dirty_page) { bpf_trace_printk("pname = %s ino = %ld index = %ld\\n", args->name, args->ino, args->index); return 0; // always return 0 } """ # Loads eBPF program b = BPF(text=prog) print("eBPF en fonctionnement .... Ctrl-C pour annuler") b.trace_print()
- TRACEPOINT_PROBE : active le tracepoint de la fonction "write_dirty_page».
- args : structure remplie par eBPF avec les paramètres du tracepoint. Ces derniers sont obtenus du fichier format qui se trouve à :
/sys/kernel/debug/tracing/events/writeback/writeback_dirty_page/format
Exemples
Un simple détecteur de DDOS
Remarque : Le script suivant est une contribution que nous avons faite au projet bcc : https://github.com/iovisor/bcc/blob/master/examples/tracing/dddos.py.
Nous allons créer un détecteur de DDOS et simuler une attaque comme le montre la figure suivante :
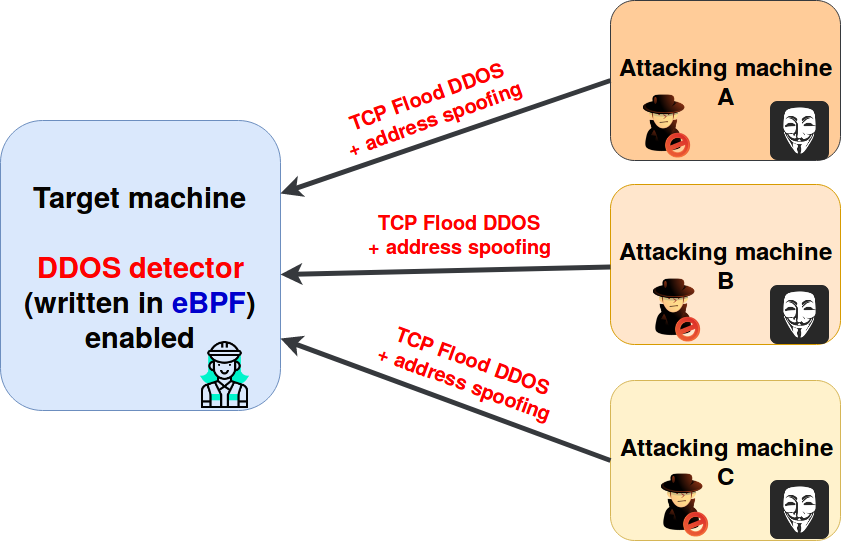
A noter : Il n'est pas nécessaire d'avoir plusieurs machines d'attaque, il est possible d'ouvrir plusieurs terminaux. Les floods DDOS peuvent être simulés avec hping3.
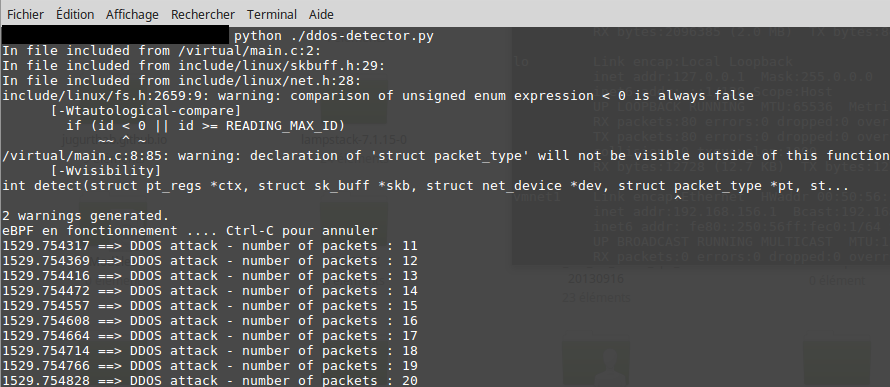
Voici une implémentation d'un détecteur DDOS, le programme lance une alerte (en affichant un message sur la console) pour notifier l'utilisateur. L'alerte est déclanchée si on reçoit 10 paquets TCP et le délai de réception entre chacun de ces derniers est inférieur à 100000ns (100ms).
Important : En pratique on ne considère pas la réception de 10 paquets comme un signe d'attaque DDOS, c'est juste un exemple pour simplifier les tests. Par contre le nombre de paquets et les délais de réception entre chaque paquet peuvent être configurés selon vos besoins.
from bcc import BPF # prog will store the eBPF C program prog = """ #include <linux/skbuff.h> #include <uapi/linux/ip.h> // Create a MAP BPF_HASH(compteur_packet_recu); // equivalent a BPF_HASH(compteur); /* struct pt_regs *ctx exists because it is mantadory to be able to use the parameters of the function*/ int detect(struct pt_regs *ctx, struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){ u64 compteur_packet_recu_nombre = 0, compteur_packet_recu_nombre_inter=1, *compteur_packet_recu_nombre_ptr; u64 compteur_packet_recu_temps_index = 1, compteur_packet_recu_temps_inter=0, *compteur_packet_recu_temps_ptr; // Get number of packets compteur_packet_recu_nombre_ptr = compteur_packet_recu.lookup(&compteur_packet_recu_nombre); // Get time of last packet compteur_packet_recu_temps_ptr = compteur_packet_recu.lookup(&compteur_packet_recu_temps_index); if(compteur_packet_recu_nombre_ptr != 0 && compteur_packet_recu_temps_ptr != 0){ compteur_packet_recu_nombre_inter = *compteur_packet_recu_nombre_ptr; compteur_packet_recu_temps_inter = bpf_ktime_get_ns() - *compteur_packet_recu_temps_ptr; if(compteur_packet_recu_temps_inter < 100000){ compteur_packet_recu_nombre_inter++; } else { compteur_packet_recu_nombre_inter = 0; } if(compteur_packet_recu_nombre_inter > 10) bpf_trace_printk("DDOS attack - number of packets : %d\\n", compteur_packet_recu_nombre_inter); compteur_packet_recu.delete(&compteur_packet_recu_nombre); compteur_packet_recu.delete(&compteur_packet_recu_temps_index); } compteur_packet_recu_temps_inter = bpf_ktime_get_ns(); compteur_packet_recu.update(&compteur_packet_recu_nombre, &compteur_packet_recu_nombre_inter); compteur_packet_recu.update(&compteur_packet_recu_temps_index, &compteur_packet_recu_temps_inter); return 0; // always return 0 } """ # Loads eBPF program b = BPF(text=prog) # Attach kprobe to kernel function ip_rcv and sets detect as kprobe handler b.attach_kprobe(event="ip_rcv", fn_name="detect") # displays a message when eBPF starts print("eBPF en fonctionnement .... Ctrl-C pour annuler") while 1: (task, pid, cpu, flags, ts, msg) = b.trace_fields() print("%f ==> %s " % (ts, msg))
Le code peut sembler difficile mais voici l'explication dans les grandes lignes :
- Utilisation d'une structure Map : Notre programme doit mémoriser le nombre de paquets reçus et les temps de réception. Les structures Maps sont le seul moyen de persistance sous eBPF, ce qui explique la ligne : BPF_HASH (compteur_packet_recu).
- Récupérer le nombre de paquets et le timestamp de réception : les lignes compteur_packet_recu.lookup(&compteur_packet_recu_nombre) et compteur_packet_recu.lookup(&compteur_packet_recu_temps_index) lisent le nombre de paquets reçus (ne désigne pas le nombre total de paquets comme on le verra plus tard dans le code) et le timestamp du dernier paquet reçu respectivement.
- Le détecteur DDOS : Les seules lignes qui constituent la logique du détecteur DDOS sont les suivantes :
if(compteur_packet_recu_temps_inter < 100000){ compteur_packet_recu_nombre_inter++; } else { compteur_packet_recu_nombre_inter = 0; } if(compteur_packet_recu_nombre_inter > 10) bpf_trace_printk("DDOS attack - number of packets : %d\\n", compteur_packet_recu_nombre_inter);
- Vérifier si la différence entre le timestamp de réception du paquet actuel par rapport au précédent est inférieur à 100ms.
- Inférieur à 100ms : un compteur comptabilise le nombre de paquets que l'on reçoit trop rapidement (moins de 100ms entre chaque paquet).
- Supérieur à 100ms : le compteur est remis à zéro car les délais de réception sont normaux.
- Si le nombre de paquets est supérieur à 10, on envoie un message à l'utilisateur.
- Vérifier si la différence entre le timestamp de réception du paquet actuel par rapport au précédent est inférieur à 100ms.
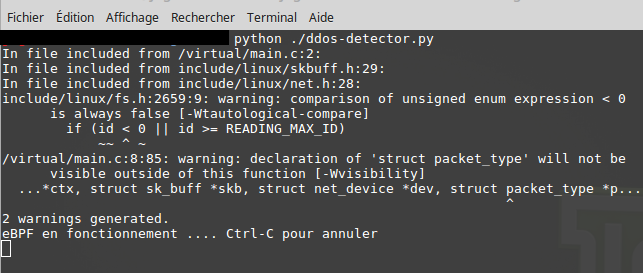
Voici des éléments permettant de tester notre détecteur de DDOS.
Il faut commencer par démarrer notre programme eBPF sur une machine cible (voir l'image ci dessous).
Lorsque le script est démarré, nous choisissons une machine permettant de lancer l'attaque.
Nous allons installer hping3, un programme capable de créer un grand nombre de packets TCP/IP personnalisés et les envoyer vers une cible.
$ sudo apt-get install hping3
Nous démarrons plusieurs terminaux, et lançons dans chacun d'entre eux la commande suivante :
$ sudo hping3 Adresse_IP_Machine_Cible -S -A -V -p 443 -i u100
Quelques instants après le début de l'attaque, eBPF doit commencer à afficher des alertes comme le montre la figure suivante :
Un traceur d'allocation mémoire
Nous allons réaliser un traceur d'accès mémoire, nous allons juste suivre deux fonctions : kmem_cache_alloc et kmem_cache_free. Ces deux dernières existent déjà comme tracepoints dans le fichier /sys/kernel/debug/tracing/events/kmem.
Important : Il faut utiliser les deux fichiers /sys/kernel/debug/tracing/events/kmem/kmem_cache_free/format et /sys/kernel/debug/tracing/events/kmem/kmem_cache_alloc/format pour récupérer les paramètres des deux fonctions.
Voici un exemple de code pour le faire :
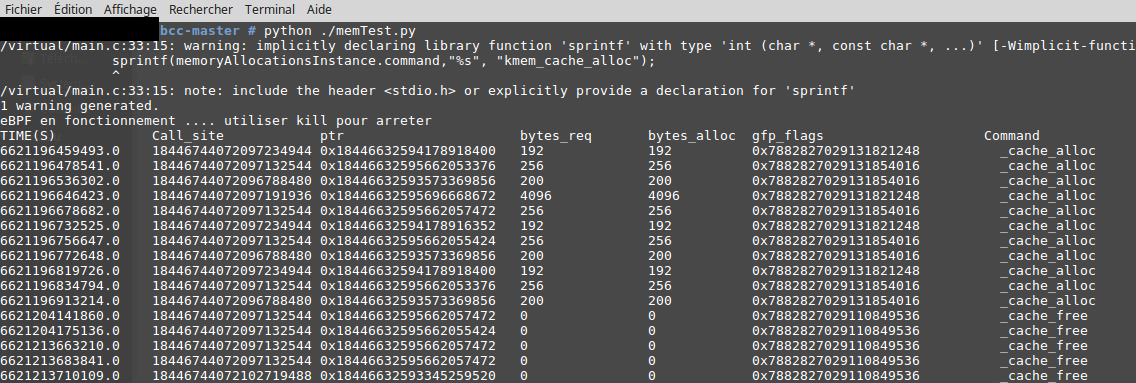
from bcc import BPF import ctypes as ct # prog will store the eBPF C program counter = 0; prog = """ struct memory_allocations { u64 timestamp; u64 call_site; u64 ptr; u64 bytes_req; u64 bytes_alloc; u32 gfp_flags; char command[30]; }; /* Remember : When using tracepoints we need to make use of /sys/kernel/debug/tracing/events directory. For example : the parameters of the function kmem_cache_alloc are defined in /sys/kernel/debug/tracing/events/kmem/kmem_cache_alloc/format */ BPF_PERF_OUTPUT(events); BPF_PERF_OUTPUT(events_free); TRACEPOINT_PROBE(kmem, kmem_cache_alloc) { struct memory_allocations memoryAllocationsInstance = {}; memoryAllocationsInstance.timestamp = bpf_ktime_get_ns(); memoryAllocationsInstance.call_site = args->call_site; memoryAllocationsInstance.ptr = (u64)args->ptr; memoryAllocationsInstance.bytes_req = args->bytes_req; memoryAllocationsInstance.bytes_alloc = args->bytes_alloc; memoryAllocationsInstance.gfp_flags = args->gfp_flags; sprintf(memoryAllocationsInstance.command,"%s", "kmem_cache_alloc"); events.perf_submit(args, &memoryAllocationsInstance, sizeof(memoryAllocationsInstance)); return 0; } TRACEPOINT_PROBE(kmem, kmem_cache_free) { struct memory_allocations memoryFreeInstance = {}; memoryFreeInstance.timestamp = bpf_ktime_get_ns(); memoryFreeInstance.call_site = args->call_site; memoryFreeInstance.ptr = (u64)args->ptr; memoryFreeInstance.bytes_req = 0; memoryFreeInstance.bytes_alloc = 0; memoryFreeInstance.gfp_flags = 0; sprintf(memoryFreeInstance.command,"%s", "kmem_cache_free"); events_free.perf_submit(args, &memoryFreeInstance, sizeof(memoryFreeInstance)); return 0; } """ # Loads eBPF program b = BPF(text=prog) class Data(ct.Structure): _fields_ = [("timestamp", ct.c_ulonglong), ("call_site", ct.c_ulonglong),("ptr", ct.c_ulonglong),("bytes_req", ct.c_ulonglong),("bytes_alloc", ct.c_ulonglong),("gfp_flags", ct.c_ulonglong), ("command", ct.c_char * 30)] # Show message when ePBF stats print("eBPF en fonctionnement .... utiliser kill pour arreter") print("%-18s %-20s %-24s %-15s %-12s %-28s %-30s" % ("TIME(S)", "Call_site", "ptr", "bytes_req", "bytes_alloc", "gfp_flags", "Command")) def afficher_evenement(cpu, data, size): evenement = ct.cast(data, ct.POINTER(Data)).contents print("%-18.1f %-20.0f 0x%-22.0f %-15.0f %-12.0f 0x%-28d %-30s" % (evenement.timestamp, evenement.call_site, evenement.ptr, evenement.bytes_req, evenement.bytes_alloc, evenement.gfp_flags, evenement.command)) b["events"].open_perf_buffer(afficher_evenement) b["events_free"].open_perf_buffer(afficher_evenement) while(1): # read messages from trace_pip and display them to user b.perf_buffer_poll()
La seule nouveauté du code est l'usage de deux canaux PERF (BPF_PERF_OUTPUT(events), BPF_PERF_OUTPUT(events_free)) pour envoyer les données associées à kmem_cache_alloc et kmem_cache_free respectivement.
Le résultat du script précédent doit être semblable à la figure suivante :
Tracepoint ou Kprobe?
Il est toujours recommandé d'utiliser les tracepoints plutôt que les kprobes. En effet les tracepoints sont plus stables car ils changent rarement au fils des années, contrairement au kprobes qui dépendent du nom de la fonction et de ses paramètres (ces derniers changent souvent et donc la kprobe va planter dans ce cas).
Conclusion
Cet article a permis de nous faire découvrir les bases du traceur eBPF. Nous avons vu les principaux concepts (comment tracer, comment envoyer les données à l'utilisateur, ..., etc) , ce qu'il faut appréhender, et nous avons même créé nos propres scripts de zéro avec bcc.
Nous pouvons aller encore plus loin avec la documentation officielle : https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md et la liste des API bcc : https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md.