Dans cet article, nous allons discuter de l'intérêt ainsi que des avantages et inconvénients d’utiliser un noyau Linux temps réel. L'objectif de cet article n’est pas de décrire ce qu’est le temps réel mais pourquoi et comment l’utiliser.
Aux lecteurs curieux et intéressés par le temps réel, je recommande le livre de Christophe Blaess, Solutions temps réel sous Linux.
Introduction
Historique
La notion de temps réel a commencé à apparaître dans les années 60 dans le domaine de l’aérospatial. En effet, l’un des premiers systèmes embarqués temps réel fut l’Apollo Guidance Computer conçu par le MIT permettant du traitement temps réel des données recueillies lors du vol. La notion de temps réel a cependant bien évolué jusqu'à maintenant.
De nos jours, de nombreux systèmes requièrent des performances dites temps réel. En effet, le marché des systèmes embarqués est en pleine croissance et le besoin de solutions embarquées temps réel augmente en conséquence. Le temps réel se retrouve en particulier dans les domaines suivants :
- Automobile
- Automatique industrielle
- Télécommunications
- Santé/Médical
- Aéronautique/Aérospatial
Qu’est ce que le temps réel ?
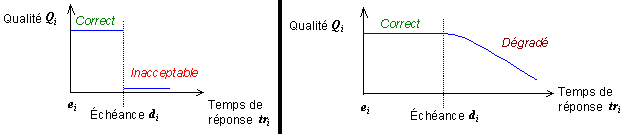
Il ne faut pas confondre temps réel avec vitesse. Par exemple le système de commande d’un avion nécessitera un temps de réponse de l’ordre de la microseconde alors le système de contrôle d’une chaîne de production nécessitera un temps de réponse de l’ordre de la milliseconde. En revanche, il devront tous deux répondre dans un laps de temps défini et ne pas le dépasser.
Il existe plusieurs notions de temps réel : Le temps réel strict (hard real time) et le temps réel souple (soft real time).
Le temps réel strict pénalise le non-respect d'une échéance par l'émission d'une erreur. La réponse du système est donc considérée comme erronée. En revanche un temps réel souple tolère une certaine marge de dépassement.
Les solutions temps réel
Plusieurs solutions temps réel sont disponibles aujourd'hui, propriétaires comme libres. En voici quelques exemples :
- FreeRTOS
- QNX
- VxWorks
On peut ensuite lister les solutions avec noyaux hybrides qui présentent d’autres avantages. Certaines de ces solutions permettent d'utiliser un noyau Linux et d’y installer à côté un noyau temps réel. On peut citer :
- Xenomai (Cobalt), Xenomai Mercury est simplement l’utilisation de l'API Xenomai sur un noyau Linux patché PREEMPT_RT.
- RTAI
Xenomai se distingue par ses performances ainsi que la possibilité d'utiliser son API sans avoir obligatoirement à utiliser son co-noyau Xenomai Cobalt. A cet effet, Xenomai se décline en deux versions : Cobalt (co-noyau) et Mercury.
Cobalt est la version la plus intéressante si l'on veut faire du temps réel strict. Cobalt utilise le patch I-pipe qui installe un pipeline redistribuant les interruptions entre le noyau linux (pour les interruptions non temps réel) et le noyau Cobalt (pour les interruptions temps réel). Attention cependant, il est important de regarder la compatibilité du patch avec le matériel utilisé.
Mercury lui, permet d'utiliser l'API Xenomai sur un noyau linux patché PREEMPT_RT. Mercury est plus simple à implémenter que Cobalt mais reste moins performant.
Le noyau Linux mainline quant à lui possède quelques briques de base nécessaire au temps réel, comme par exemple un scheduler qui propose des politiques de scheduling temps réel.
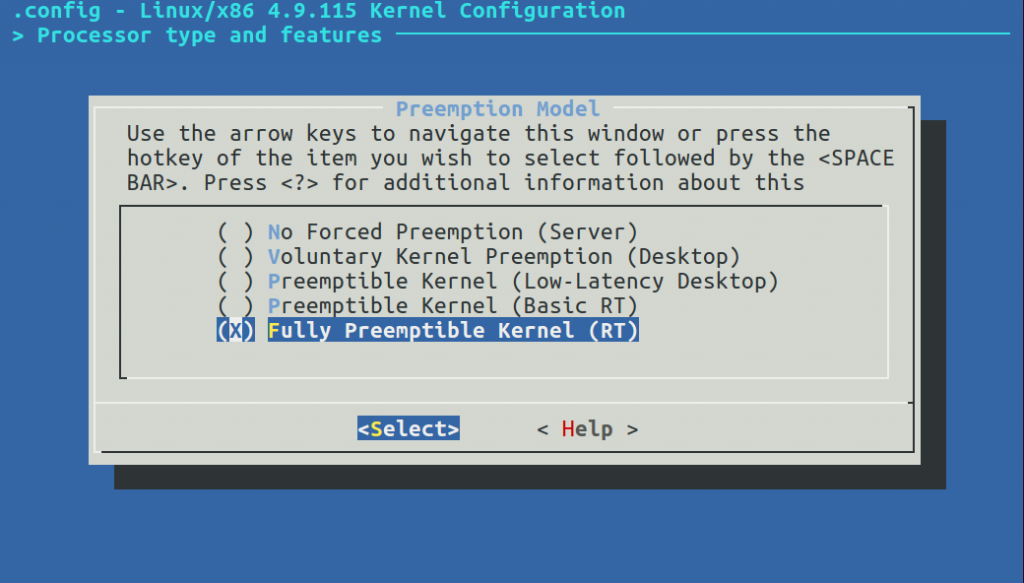
En effet, dans les options de kernel, on peut choisir la préemptibilité du noyau linux. Par défaut, seulement 3 options sont disponibles, la meilleure de ces trois options pour s'approcher d'un comportement temps réel étant la préemptibilité Low-Latency. Cependant si l’on veut vraiment faire du temps réel, il faudra se tourner vers d’autres solutions.
Il est possible d’ajouter deux autres options de configuration en patchant le kernel à l’aide du patch PREEMPT_RT. Ce patch n’est actuellement pas pris en charge par le kernel mainline mais est en bonne voie pour devenir partie intégrante du kernel dans les mois ou les années à venir.
Nous allons maintenant parcourir les changements introduits par le patch PREEMPT_RT, évaluer les performances des différentes solutions temps réel sous Linux et évoquer des exemples d’implémentation de temps réel sous linux.
Apports du patch PREEMPT_RT
Le patch PREEMPT_RT ajoute l'option de compilation du noyau CONFIG_PREEMPT_RT_FULL. Elle se traduit par l’ajout de lignes dans le code du kernel, de type :
#ifdef CONFIG_PREEMPT_RT_FULL
<code modifié RT>
#else
<code vanilla>
#endifLe principe du patch PREEMPT RT est d’autoriser la préemption partout même dans les interruptions, à l’aide de l’ajout des mécanismes que nous allons décrire ci-après.
Spinlock et Mutex
Dans le patch PREEMPT_RT, l’intérêt est de pouvoir préempter toutes les tâches, mêmes celles possédant un spinlock, pour laisser s'exécuter la tâche la plus prioritaire. Dans cette optique, le rôle du patch est donc de transformer les spinlocks actuels en sleeping spinlocks, soit en rt_mutex. En effet, les spinlocks ne sont pas préemptibles par défaut, ce qui peut poser problème lorsqu’on fait du temps réel.
On peut le voir dans le fichier <spinlock_types.h> :
#include <linux/spinlock_types_raw.h>
#ifndef CONFIG_PREEMPT_RT_FULL
# include <linux/spinlock_types_nort.h>
# include <linux/rwlock_types.h>
#else
# include <linux/rtmutex.h>
# include <linux/spinlock_types_rt.h>
# include <linux/rwlock_types_rt.h>
#endifEt dans le fichier <linux/spinlock_types_rt.h> :
typedef struct spinlock {
struct rt_mutex lock;
unsigned int break_lock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} spinlock_t;Voici ci-dessous le fonctionnement des spinlocks dans un kernel mainline. Prenons l’exemple d’un programme possédant deux threads, tout deux s’exécutant sur un même coeur. Le premier thread (VERT), se lance jusqu'à rencontrer une zone de code protégée par un spinlock. Pendant ce temps, le thread 2 (BLEU), plus prioritaire est prêt à s'exécuter mais comme le thread 1 est dans un spinlock, le thread 2 devra attendre la fin de la zone de code protégée par un spinlock.
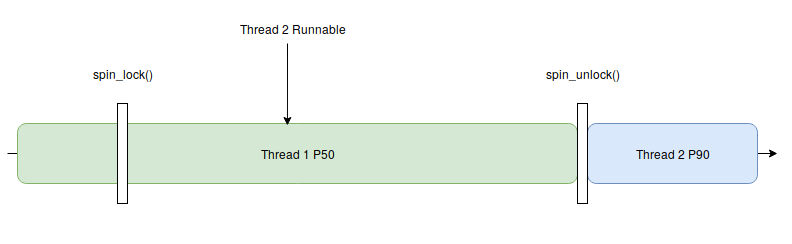
Maintenant avec le patch PREEMPT_RT, on voit que le scheduler donne la main au thread 2 possédant une priorité plus élevée. Ces changements peuvent être lus sur la documentation de la fondation Linux, on peut voir notamment qu’un spinlock se comporte donc comme un rt_mutex (“In order to minimize the changes to the kernel source the existing spinlock_t datatype and the functions which operate on it retain their old names but, when PREEMPT_RT is enabled, now refer to an rt_mutex lock”) :
https://wiki.linuxfoundation.org/realtime/documentation/technical_details/sleeping_spinlocks
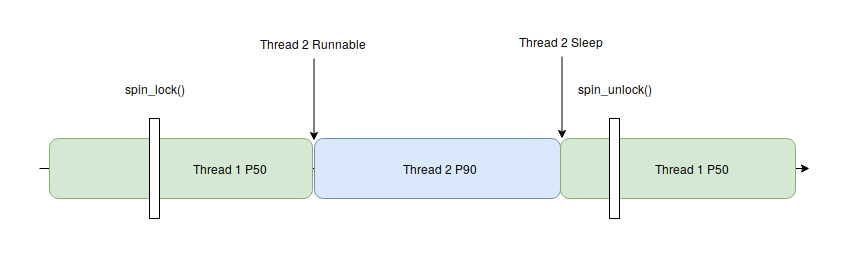
Raw spinlock
Bien que les spinlocks deviennent des mutex, il reste des endroits dans le kernel où il est nécessaire d’avoir recours à de vrais spinlocks. En effet, certains endroits du kernel ne devraient pas être préemptibles car ils sont vraiment critiques.
De plus, les spinlocks ont l'avantage d’être plus rapides que les mutex. Pour cela, il existe les raw_spinlocks qui sont en réalité les spinlocks du kernel classique non patché.
Ils ont été ajoutés au kernel mainline mais ne sont d’aucune utilité dans un kernel non patché. Il faut cependant prendre garde à leur utilisation dans un système temps réel. En effet, les raw_spinlocks désactivent la préemption et les interruptions, ce qui peut engendrer des latences non désirées et donc dégrader l’aspect temps réel du système.
Threaded Interrupts
Comme l’objectif du patch PREEMPT_RT est de rendre le kernel aussi préemptible que possible, il paraît normal de modifier le fonctionnement des interruptions. Nous allons tout d’abord revoir le fonctionnement classique des interruptions.
Interruptions classiques : Dans le kernel linux, lorsque une interruption survient, c’est à dire lorsqu’un périphérique externe change d’état (des données sur le port ethernet, le changement d'état d'une broche GPIO, etc.), le périphérique envoie un signal au gestionnaire d’interruptions APIC (Advanced Programmable Interrupt Controler).
Le gestionnaire transmet ensuite une requête d’interruption IRQ (Interrupt Request) au processeur. Ce dernier s’arrête, sauvegarde son contexte puis traite l’interruption concernée. Pour traiter l’interruption, plusieurs méthodes existent, mais la plus courante est celle des top-half et bottom-half.
Top-half et bottom-half interrupts handler : Pour traiter une interruption en évitant de monopoliser une unité de calcul, le moyen le plus utilisé est celui des top-half et bottom-half.
Ce mécanisme consiste à exécuter le top-half au moment de l’interruption, qui effectuera le minimum vital au traitement de l’exécution. Il programmera ensuite dans une file d’exécution un handler bottom-half qui traitera l’interruption proprement une fois qu’elle sera démasquée dans l’APIC et que le processeur disposera de temps de travail disponible.
Cette méthode permet ainsi de pouvoir gérer une succession rapide d’interruptions vu que le bottom-half est programmé dans tous les cas.
Threaded interrupts : Pour permettre au système de gérer des contraintes temps réel, le patch PREEMPT_RT met en place des threaded interrupts.
Les threaded interrupts reprennent le concept top-half bottom-half, mais remplacent le handler du bottom-half par un thread. Cela permet de donner une priorité au thread et de le préempter si un thread avec une priorité plus élevé est runnable.
Héritage de priorité
Le dernier changement important à noter est l’ajout de l’héritage de priorité pour les mutex et les spinlock. Pour illustrer l’héritage de priorité et son importance, regardons le cas suivant.
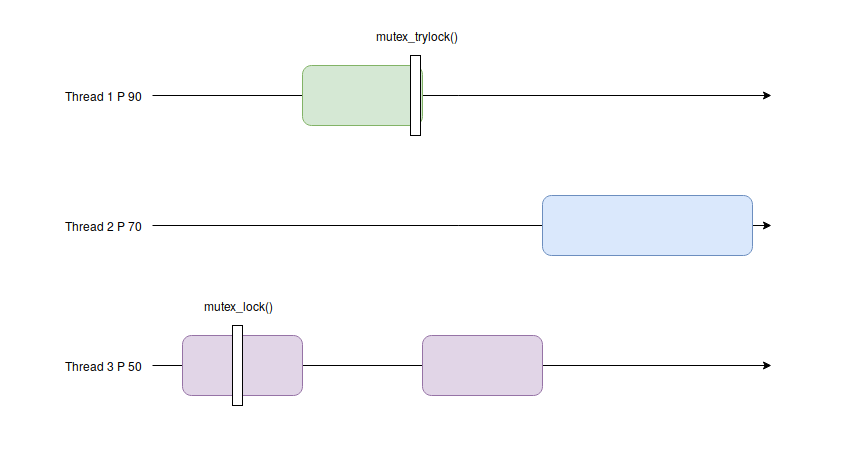
Tout d’abord, sans héritage. On peut voir sur le schéma ci-dessous, que le thread 3 possède initialement un mutex. Le thread 1 devenant runnable, commence à exécuter son code jusqu’à ce qu’il demande le mutex tenu par le thread 3, ce qui provoque son endormissement. Le thread 3 reprend alors son exécution. Cependant, avant d’avoir pu relâcher le mutex, le scheduler le préempte en faveur du thread 2 qui s’exécute pour une période indéfinie.
On constate alors que le thread 1 qui a la priorité la plus élevée ne pourra pas s’exécuter, ce qui par conséquent pose un problème lorsqu’on fait du temps réel du fait que le thread avec la plus grande priorité ne s’exécute pas, on appelle ça une famine.
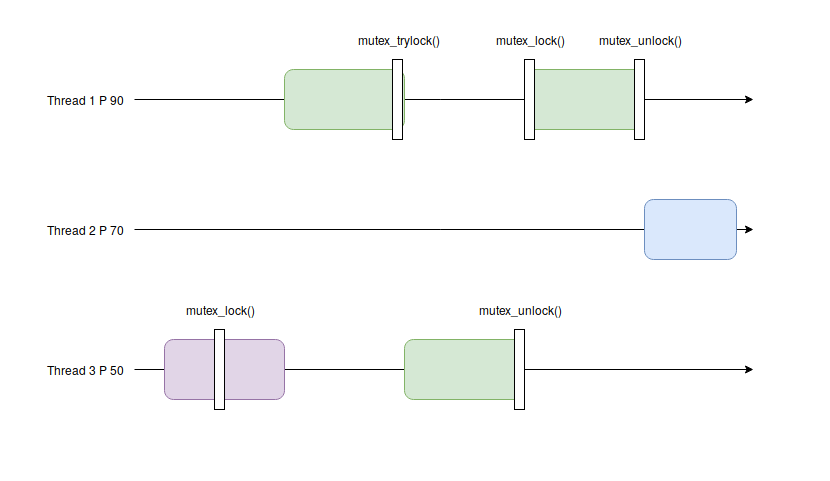
Dans ce second exemple avec l’héritage de priorité, on peut voir comme tout à l’heure que le thread 3 possède initialement le mutex. Mais lorsque le thread 1 demande le mutex possédé par le thread 3, le thread 3 hérite de la priorité du thread 1 ce qui lui permet de relâcher le mutex pour permettre au thread 1 de s’exécuter, puis le thread 2 pourra s’exécuter.
Implémentation du temps réel sur noyau Linux
Les options du noyau Linux
L’implémentation du temps réel sur noyau linux est relativement simple, mais l’obtention de performances optimales est conditionnée à la modification d’options annexes. Durant les phases d’évaluation des différentes solutions temps réel et de leurs performances, nous avons constaté que certaines options impactaient les performances plus que d’autres.
Power Management
En contexte temps réel, l’important est d’avoir un système réactif qui puisse réagir à la moindre interruption externe au système. L'activation du power management sur le CPU cause un risque d'augmentation de la latence du CPU. En effet, lorsque le power management est activé, le CPU va adapter sa fréquence pour économiser de l’énergie.
Cette option reste cependant intéressante lorsque l’on fait de l’embarqué, au vu de la durée des batteries actuelles, mais empêche cependant d'obtenir des performances temps réel. Il peut être intéressant d'utiliser le power management sur certains cœurs (cela peut se faire au moment du boot comme pour les timers ci-après) et d'utiliser les autres cœurs pour toutes les tâches temps réels.
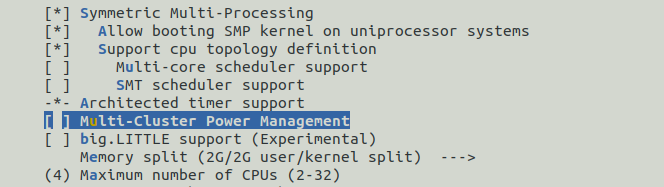
Pour désactiver le power management, il faut tout d’abord désactiver le multi-core scheduler support. En effet, ce dernier nous empêche de retirer le power management.
- SCHED_MC [=n]
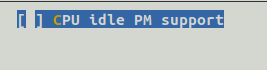
Une fois le multi-core scheduler support désactivé, on peut maintenant désactiver le CPU Frequency scaling et le CPU Idle. Le CPU Frequency scaling permet de choisir le governor à utiliser pour gérer la fréquence du CPU, ce qui est inutile dans notre cas : nous souhaitons que tous les cœurs tournent à 100% afin de maximiser les performances. En revanche, cela implique une consommation plus élevée. Il se peut, si vous avez un processeur qui supporte l’ACPI, que l’option CPU Idle ne soit pas désactivable, ce que traitera le paragraphe suivant.
- CPU_FREQ [=n]
- CPU_IDLE [=n]


Sur certains processeurs, comme ceux d’intel, l’ACPI (Advanced Configuration and Power Interface) gère le power management. Il faut donc désactiver l’ACPI seulement pour le processeur, car une désactivation pour d’autres composants pourrait empêcher le système de démarrer correctement. De plus, sa désactivation est un préalable à celle du CPU Idle.
- ACPI_PROCESSOR [=n]
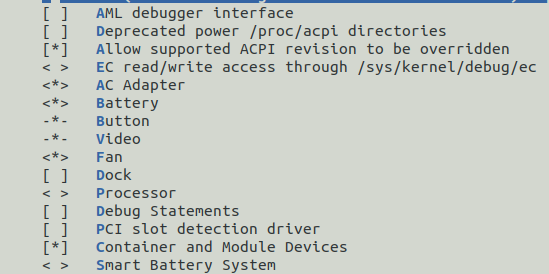
SMP
Si votre système ne possède qu’un seul cœur, cette section ne vous concerne pas, il faudra donc désactiver cette option.
Le SMP (Symmetric multi-processing), permet à un système possédant plusieurs cœurs de les utiliser et donc d'exécuter plusieurs tâches à la fois. Le problème de posséder plusieurs cœurs est qu'ils partagent des zones mémoires et notamment de la mémoire cache L2 (cela dépend de l’architecture du processeur). Le fait de partager de la mémoire augmente le temps d'accès à la zone mémoire. Pour éviter ce problème, il est conseillé de bien gérer les affinités des tâches et des processus. Pour activer le multi-processing il suffit de choisir l’option Symmetric multi-processing support.
- SMP [=y]
Timers
Ensuite, nous devons paramétrer les timers pour obtenir une plus grande réactivité. Tout d’abord, il faut activer le timer haute résolution qui fournit une meilleure précision pour tous nos programmes user-space.
- HIGH_RES_TIMERS [=y]

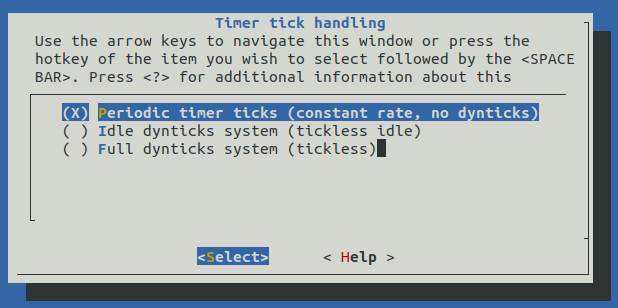
Ensuite, pour éviter au système de se mettre en veille, il faut laisser les timers interrompre le système périodiquement afin de ne pas manquer d'événements importants. Il faut donc modifier l’option Timer tick handling comme on peut le voir ci-dessous, et choisir l’option Periodic timer ticks. Il peut être intéressant de choisir cette option pour certains cœurs, dans ce cas il faudra donner les options de boot suivantes pour isoler les cœurs et les rendre tickless : "isolcpus=2,3 nohz_full=2,3"
- HZ_PERIODIC [=y]
Les impacts sur le développement applicatif et le système
Affinités
Lorsque l’on fait du temps réel sous linux, il est important de gérer l’affinité de ses tâches et des interruptions.
La première chose à faire, surtout si l’on est en SMP, est de modifier l’affinité des interruptions du système dans /proc/interrupts pour empêcher les migrations de cœur qui augmentent la latence. Il est préférable de regrouper certaines interruptions sur le même CPU pour réserver les autres CPUs à notre application temps réel.
Pour modifier l'affinité d'une interruption, il faut modifier le pseudo-fichier /proc/irq/<NumeroIRQ>/smp_affinity à l'aide de la commande :"echo 8 > /proc/irq/127/smp_affinity" pour par exemple mettre l'interruption 127 sur le CPU 4. Ce fichier contient en effet un masque binaire définissant le ou les cpus à utiliser en cas d'interruption. Par exemple 0001 représente le CPU 0 tandis que 1001 représente les CPUs 0 et 4. Il est important de noter que le fichier /proc/irq/NumeroIRQ/smp_affinity attend une valeur en hexadécimal, ce qui explique la valeur 8 précédente.
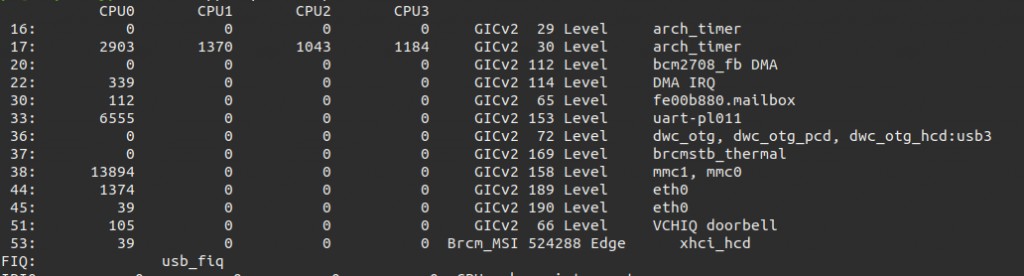
On peut voir ci-dessous les interruptions et leur nombre d'occurences sur chaque cpu de ma raspberry pi 4 à l'aide de la commande "cat /proc/interrupts".
Lors du développement applicatif d’une solution temps réel, il est important de bien choisir l’affinité de ses threads et de son processus principal. Pour les threads, il existe la fonction pthread_attr_setaffinity_np() et pour le processus principal, on peut utiliser la commande taskset ou la fonction sched_setaffinity().
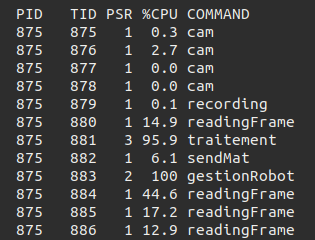
Pour vérifier l’utilisation de chaque thread de son programme, on peut utiliser la commande suivante : “watch -n 1 ps -p $(pidof monProgramme) -L -o pid,tid,psr,pcpu,comm”. Cela permet de lister pour un PID donné, tous les threads présents et d'afficher sur quel cœur ils s’exécutent. On peut voir ci-dessous le résultat de cette commande sur un programme personnel.
La colonne PID représente le PID du programme, le TID celui du thread, PSR indique sur quel cœur le thread s’exécute et %CPU sa consommation CPU. Enfin, la colonne COMMAND permet de connaître le nom du thread si vous avez utilisé la fonction pthread_setname_np().
Il est recommandé de bien connaître l’architecture de son processeur, et d'établir un plan d'affectation des ressources : laisser un cœur pour le système (le coeur 0), et répartir les activités sur les autres cœurs.
Real Time Throttling
Lorsque vous exécutez une application temps réel sur un système temps réel, par défaut le système ne donne pas accès à 100% du CPU. En effet, le scheduler temps réel ne permet à un processus que de consommer 95% du temps CPU. Ces paramètres sont régis par les pseudo fichiers suivants :
- /proc/sys/kernel/sched_rt_period_us
- /proc/sys/kernel/sched_rt_runtime_us
Ces paramètres permettent d'allouer un temps de sched_rt_runtime_us sur une période de sched_rt_period_us. Par défaut ce ratio vaut 950000 µs/100000 µs, soit 95%. Cela permet d'éviter qu'une application erronée ne prenne tout le CPU et empêche le système de réagir à d'autres événements.
En revanche, il peut être intéressant sur un système validé d'optimiser ce ratio, voire de désactiver cette option en mettant -1 dans /proc/sys/kernel/sched_rt_period_us ou en réglant sched_rt_period_us = sched_rt_runtime_us : "echo -1 > /proc/sys/kernel/sched_rt_period_us".
Performances
Afin de mesurer les performances des différentes solutions temps réel, j’ai utilisé les outils suivants :
- Un script lançant des cyclictest avec un ordonnancement SCHED_OTHER, SCHED_RR (round-robin) et SCHED_FIFO avec une priorité de 99, subissant une charge simulée par le programme stress. Chaque test a été joué durant une heure.
- Un programme codé en C calculant le temps de commutation d’un thread à l’autre au moment de lâcher un mutex, sous charge et sans charge, sur même CPU. Chaque test prenant en compte 10000 commutations.
J’ai réalisé ces tests sur les systèmes suivants :
- x86_64
- Linux vanilla 4.14.71
- Linux vanilla 4.14.71 PREEMPT_RT
- Xenomai Cobalt 3.0.8 sous linux vanilla 4.14.71
- Xenomai Mercury 3.0.8 sous linux vanilla 4.14.71 PREEMPT_RT
- Raspberry pi 3B, arm 64bits
- Linux rpi 4.14.71
- Linux rpi 4.14.71 PREEMPT_RT
- Xenomai Cobalt 3.0.8 sous linux rpi 4.14.71
- Xenomai Mercury 3.0.8 sous linux rpi 4.14.71 PREEMPT_RT
Cyclictest
Tout au long de cette partie, je ne vais parler que de l’ordonnancement SCHED_FIFO car ses performances sont quasi équivalentes à celles de l’ordonnancement round-robin, et l'ordonnancement SCHED_OTHER ne concerne pas le temps réel.
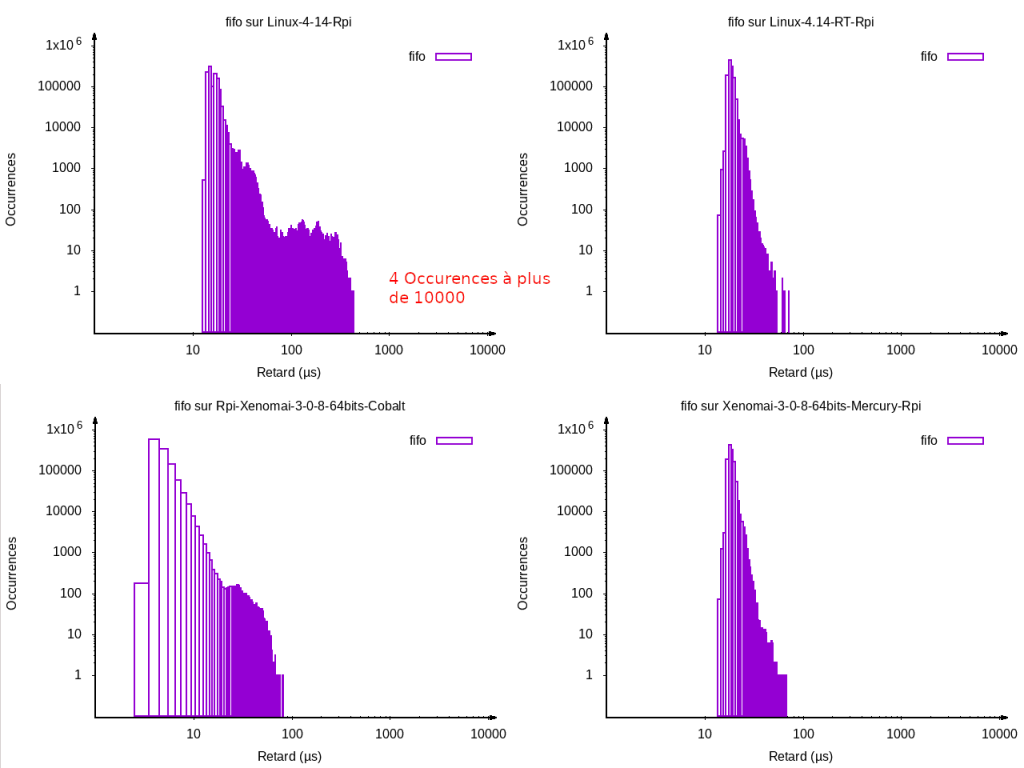
On peut voir sur cette première série de benchmarks les différences entre les différents systèmes. On remarque que seul le kernel linux classique dépasse les 400 µs de latences et que les autres ne dépassent pas les 100 µs. Attention cependant, sur le kernel normal, il y a des pics en dehors du graphique à plus de 10000 µs comme indiqué sur le graphique, ce qui pose donc le problème du déterminisme du système. Avec les trois autres systèmes, le max ne dépasse pas les 100 µs.
On peut ensuite voir que les performances sont sensiblement équivalentes entre un système sous Xenomai Mercury et un système patché PREEMPT RT. Enfin la meilleure performance vient du système sous Xenomai Cobalt qui affiche une latence maximale sous les 10 µs avec une moyenne bien plus basse que les 2 autres, et les latences semblent mieux bornées.
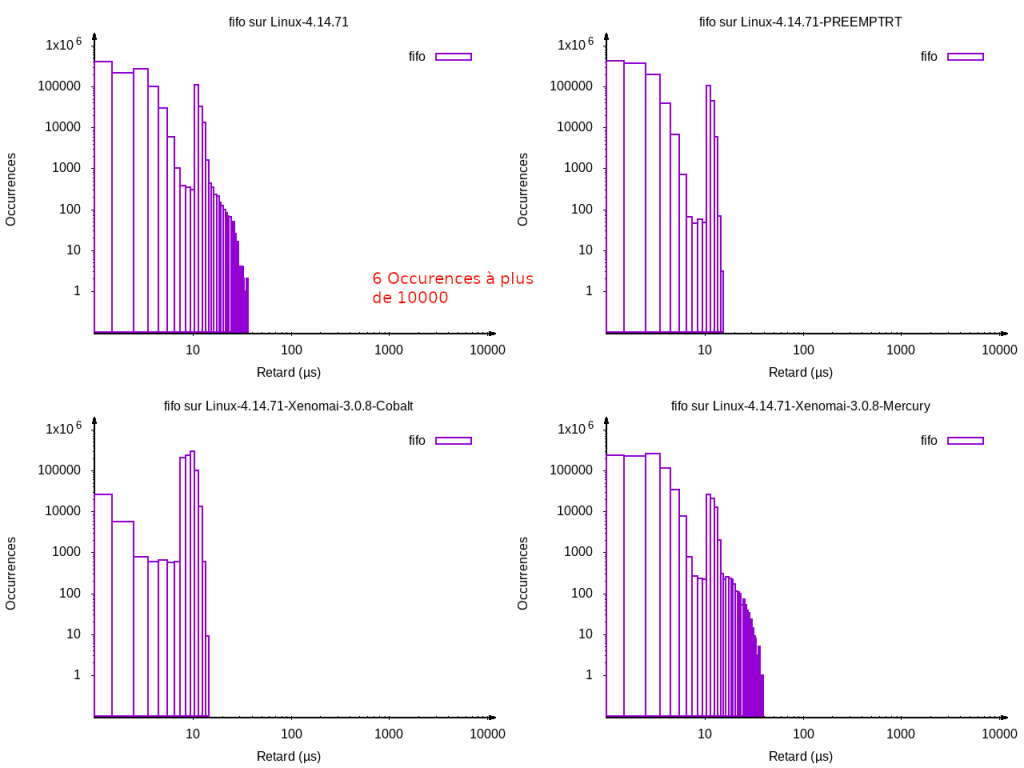
Passons maintenant sous x86_64, on peut voir que le même ordre est respecté, sauf pour Xenomai Mercury qui présente de moins bonnes performances que ses concurrents. Comme tout à l’heure le test sous linux 4.14.71 non préemptible révèle des pics à plus de 10000 µs comme indiqué sur le graphique qui sortent de la porté du graphique.
Commutations de threads
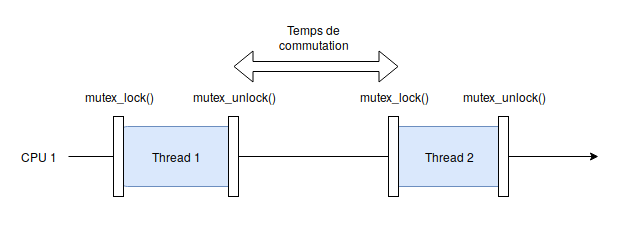
Afin de mesurer les performances de commutations, j’ai codé un petit programme qui calcule le temps que met le cpu pour changer de thread. Le principe du programme est le suivant : le thread 1 prend un mutex, puis le relâche. Le scheduler est appelé et le thread 2 se lance en prenant le mutex. Le temps séparant la fin du thread 1 du début du thread 2 est mesuré et stocké dans une variable globale protégée par le mutex. Au bout de 10000 mesures, le résultat est affiché.
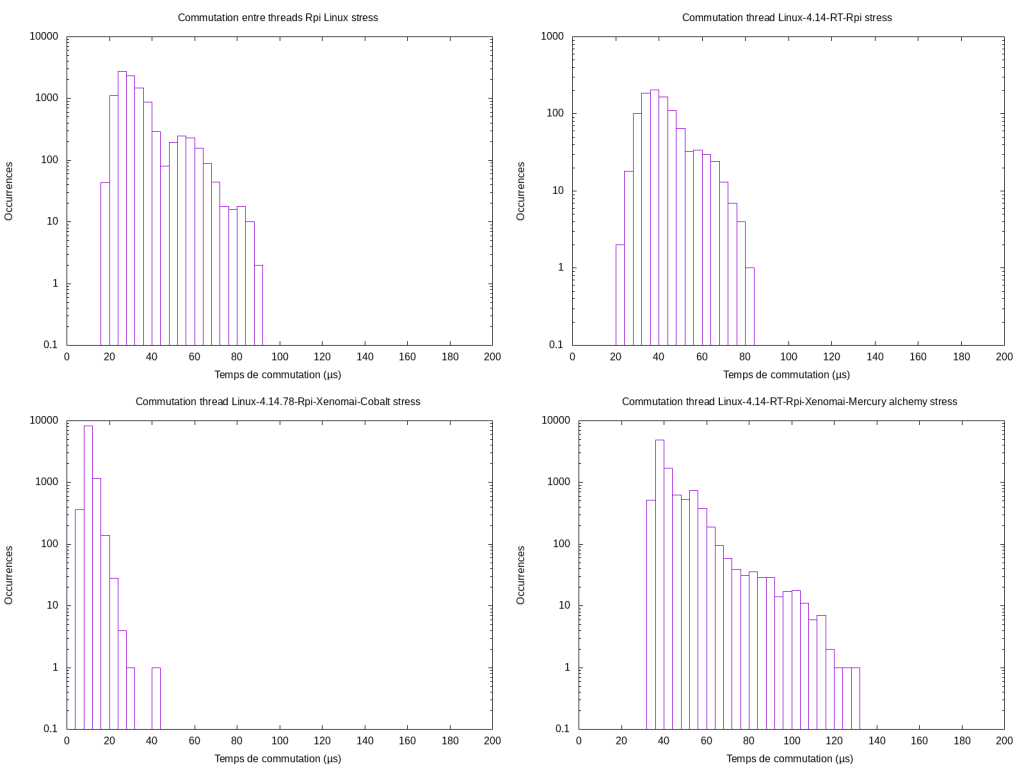
Les résultats ci-dessus montrent les différences de performances sur Raspberry Pi sous stress. On peut voir que les performances entre un linux non patché et patché PREEMPT_RT sont assez similaires, avec une valeur max de 90 µs. En revanche on peut voir un résultat assez étrange : les moins bonnes performances sont atteintes par Xenomai Mercury. Enfin, Xenomai Cobalt obtient les meilleures performances.
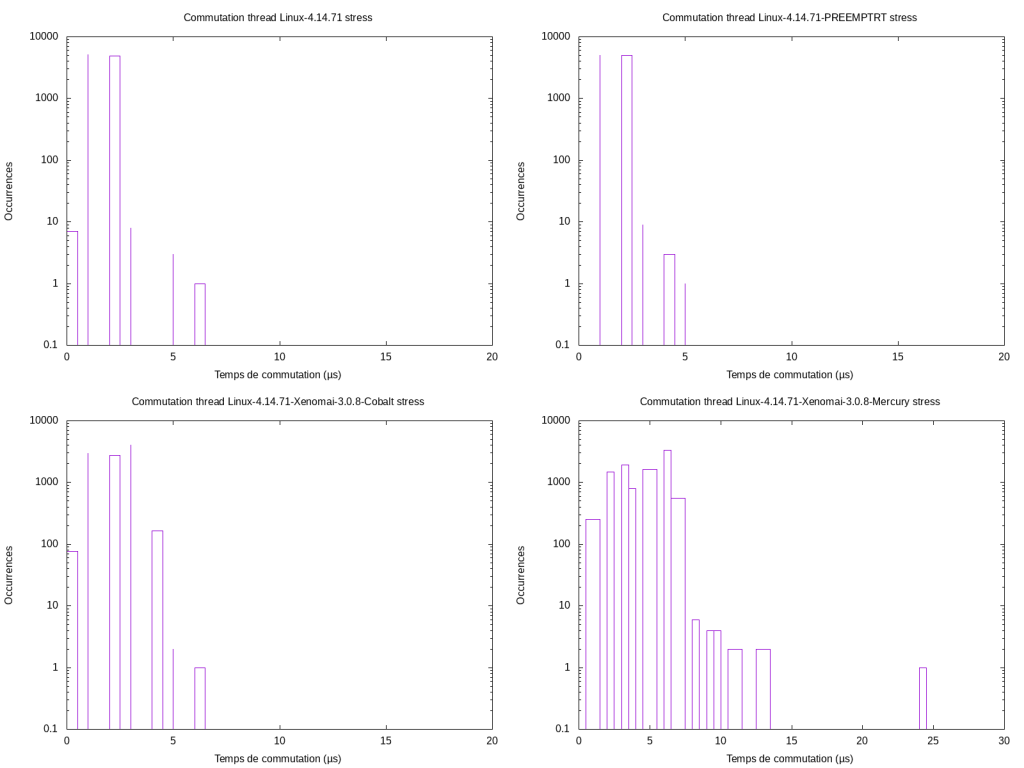
Passons maintenant sur x86_64, nous observons sensiblement les mêmes résultats que sur arm64, avec toujours un retard de performance pour Xenomai Mercury.
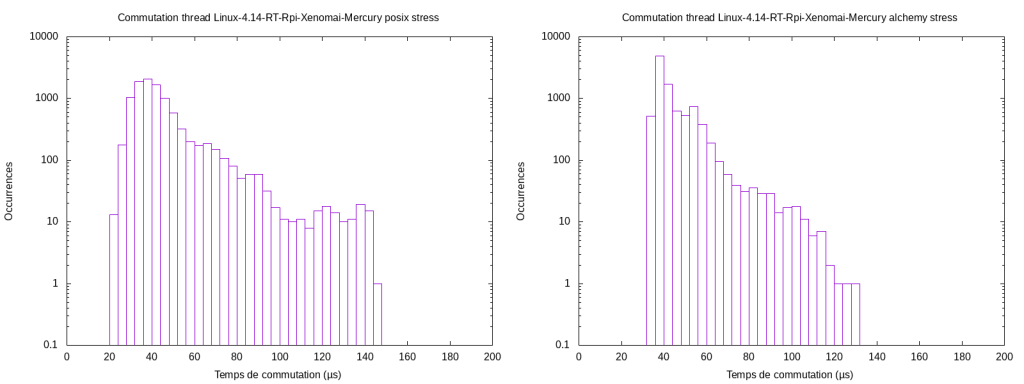
Différences entre POSIX et Alchemy (Xenomai)
Xenomai propose des skins, qui sont de petits wrappers permettant d’utiliser des APIs venant d’autres systèmes comme VxWorks ou POSIX avec Xenomai. La librairie native à xenomai est la librairie Alchemy qui est assez complète et fournit des outils très utiles comme des queues optimisées, des buffers, des pipes, des sémaphores etc…
Nous allons voir la différence de performance entre les deux skins POSIX et Alchemy, grâce à un portage du programme réalisé pour la commutation de threads sous les deux librairies. Voici ci-dessous les performances sous Xenomai Mercury. On peut voir un petit gain de performance avec la librairie native.
Conclusion
Pour conclure, nous constatons avec évidence que Xenomai Cobalt est la meilleure des solutions pour faire du Linux temps réel avec des contraintes hard real time. Cependant, nous pouvons voir que le patch PREEMPT_RT propose une solution plus facile à mettre en place que Xenomai et présente de très bonnes caractéristiques temps réel, qui ont vu une nette amélioration récemment.
On remarque par contre des résultats un peu étonnants sur Xenomai Mercury qui affiche des performances plus faibles que ses concurrents. Encore une fois, les tests réalisés ne sont pas précis à 100% au vu de leur durée et du nombre de tests réalisés, en raison d’un manque de temps.
Pour ce qui est de Xenomai et comment l'implémenter de manière optimale, voici en lien le wiki de Xenomai qui est très bien documenté :
https://gitlab.denx.de/Xenomai/xenomai/wikis/Start_Here
De plus, j’ai exposé ici quelques options à activer/désactiver au niveau du kernel, mais la configuration optimale dépendra de l’architecture utilisée et des contraintes liées au produit. Si vous êtes intéressé, vous pouvez consulter le site ci-dessous décrivant toutes les subtilités et les améliorations à faire pour mettre en place du temps réel :
http://linuxrealtime.org/index.php/Main_Page
Je vous partage également deux vidéos intéressantes sur le patch PREEMPT_RT :
- Real Time is Coming to Linux; What Does that Mean to You? - Steven Rostedt, VMware
- Embedded Linux Conference 2013 - Inside the RT Patch
- Introduction to Realtime Linux