Logging problems are key features of any complex system in order to detect and locate any unexpected behavior. On Linux system, there are lots of solutions to generate debugging information for an unexpected behavior of a userspace application (log messages, core dump).
But what could we do if there is a kernel problem ? Few solutions exist although none are trivial.
What can go wrong with a Linux kernel
In the first place, one can wonder what are the possible causes of kernel crashes, especially on embedded systems.
Here are several cases where debugging data are critical:
- Kernel crash due to hardware interrupt: this may be an invalid memory access, any memory-related problem (like DataAbort interrupts on ARM) or any unhandled hardware-related problem.
- Kernel crash due to voluntary panic: the kernel code detects a problem and may trigger a kernel panic or a kernel oops.
- Kernel scheduling problem: some issues with the preemption or with the execution of tasks (userspace or kernel thread).
- Kernel deadlock: kernel is stuck due to misuses of kernel locking mechanisms like spinlocks.
- Endless raw critical section: code disables IRQ handling and never enables it back.
Except for case 5, handling all of these problems means detecting and logging a kernel panic. Generic code exists inside the kernel Linux to detect these cases and trigger a kernel panic when they happen. The default DataAbort handler causes a kernel panic. Detecting kernel deadlock could be done using the lockup detector. Also, any non-critical error like kernel oops can be converted into a kernel panic using the kernel sysctl panic_on_oops or with the kernel boot parameter oops=panic. There is also a panic_on_warn parameter to trigger a panic when the kernel executes the WARN() macro.
One must compromise between crashing the kernel on error and the stability of the system. You should consider which is better between triggering a crash or letting the system live after this error.
On embedded systems, rebooting in case of unexpected behavior is often preferred to keeping on with a system which potentially does not fulfill its job.
Rebooting on a kernel crash could be done:
- In software by setting the panic timeout, which is the time between a panic and the effective reboot. Its is defined in the kernel configuration
CONFIG_PANIC_TIMEOUTand can also be set from kernel boot parameter. - In hardware using a watchdog. This will happen automatically since, after a crash, the hardware watchdog won't be fed anymore and it will trigger a reboot after its timeout.
Ensuring that an embedded system works properly is crucial. Therefore in order to detect the problem on products in the wild and to debug them, all available information on the issue have to be logged persistently.
The first information you may want is the kernel log buffer (aka dmesg). Getting those information will be developed as the main subjet of this article: How can we log persistently debugging information between a kernel crash and a reboot ?
Dumping the kernel log buffer
There is no easy way to write persistently something just after a kernel crash occurs. The main reason is that the kernel can't bet trusted to save the data into disk.
Depending on the physical medium used to dump the data (flash nand/nor, eMMC/SD card, SATA disk, USB disk, ...), the associated subsystem and all the drivers used to perform a dump must work correctly, even after a crash, which is impossible to ensure.
Also, when entering in panic(), all CPU are stopped and there is no more scheduling: the kernel stays in the panic function until the machine is rebooted. This means that the necessary code to perform a write on physical medium must be synchronous and never depend on scheduler which is not the case for the normal kernel paths.
Imagine that you want to dump kernel log on a eMMC and the kernel crashes while a transfer is still operating. eMMC access is protected by multiple locks (in several subsystems) and the transfer tends to be as asynchronous as possible. Writing on eMMC from panic() would have to terminate those locks and the current transfer and then perform a synchronous write on the medium using a different code-path than the one normally used, which is usually asynchronous.
Despite these constraints, logging the kernel buffer could be implemented using several approaches:
- Log continuously the kernel log buffer to an external device:
- Using the network and the netconsole driver
- Using a serial port and the console
- The log is kept persistent by an external system. On deployed embedded system, this is usually not possible.
- Specific driver implementing synchronous write:
- I found two existing drivers to perform such write: mtdoops and ramoops. If you are using a MTD or a NVRAM, this may be the easiest solution.
- MTD write is perfomed synchronously using
mtd_panic_write(). See file mtdoops.c
- Auxiliary Persistent Storage Pstore support:
- This kernel code allows to use non-volatile, dedicated storage to store debugging information
- This is currently limited to ACPI. Two LWN articles describe the implementation: here and here
- ABRT daemon has a support for these dumps
- Since version 243, systemd will automatically store any pstore data it finds at boot time to /var/lib/pstore
- Execute a new, smaller Linux system on top of the one which crashed using kexec
- Not a well known kernel feature
- Some userspace tools available
- Quite difficult to implement
This article will focus on this 4th solution: using kexec feature to boot a new Linux kernel in charge of saving debug information from the initial system. Although the other solutions are easier to use, the latter one is generic and does not depends on the physical medium used. This is also often the only solution available for ARM-based systems which do not have MTD to store these dumps.
Kexec and crashdump overview
First of all, we will discuss about kexec. This is a feature of the Linux kernel that allows booting into another system (usually another Linux kernel) from a running one. For Desktop systems, this feature is often used to perform fast warm reboots after a kernel update.
Instead of starting a Linux kernel from a bootloader, you are starting it from Linux itself. The idea is to trigger automatically a kexec when a crash occurs. The new booted system would be responsible of storing all debug data on persistent memory. Here is an overview of how kexec can be used for our needs:
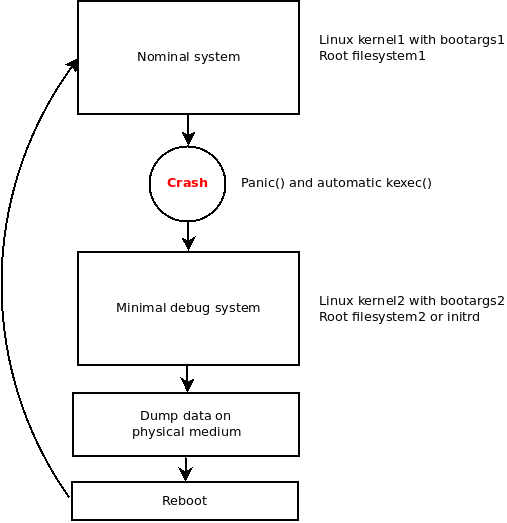
Triggering kexec from the panic() function is already implemented in the Linux kernel. A dedicated kexec image called crashdump can be used to boot this new kernel image when the initial system crashes. To enable it in your kernel build, you need to define the following configuration:
CONFIG_KEXEC=yCONFIG_CRASH_DUMP=yCONFIG_PROC_VMCORE=yCONFIG_RELOCATABLE=y
These kernel options not only execute a new kernel on crash but also keep in memory useful debugging data which are passed to the new kernel.
What could be the most complete data to perform post-crash investigation ? The answer is simple: the whole volatile memory of the system (RAM). But, if we want to keep it intact while booting a new kernel (which also uses memory), we have to reserve a memory region from the original kernel, which means from the boot of the initial system. The picture bellow describes how this initial memory region is dedicated.
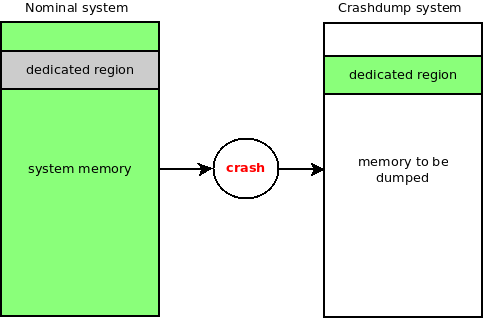
To tell the initial kernel to reserve this dedicated memory region for crashdump usage, you can use the boot parameter crashkernel=size[KMG][@offset[KMG]] as described in the documentation.
When a Linux kernel is booted after a crash, the applications launched by the second kernel are able to access the original memory through the special file /proc/vmcore. Note that this file also contains some metadata to help for debug and forensics.
To sum up, in order to dump the whole memory on a persistent memory, we can use kexec feature and define a crashdump image which will be booted when a kernel panic()occurs. To prevent the new kernel from overwriting the memory of the crash system, a memory region dedicated to crashdump is reserved at bootime.
Interacting with the kexec kernel part from userspace is done through special syscalls which are called by userspace tools provided by the kexec-tools package. Make sure to use a version compatible with your kernel version.
The kexec utility can be used to load the crashdump kernel in memory and to define its boot parameters. It can also be used to test the kexec feature by booting on-demand to the new kernel. See the man page of kexec for details.
There is also a vmcore-dmesg utility which can be used to extract the kernel log buffer from a vmcore. We will see another utility called crash later that can do the same thing.
Implementation of the vmcore backup
To understand what is needed to boot a new Linux kernel, you can refer to what your bootloader is doing initially. On embedded system, here is the minimal things a bootloader must do:
- Load the kernel binary in memory (zImage)
- For devicetree-enabled products, load the DTB in memory (myboard.dtb)
- Define the kernel boot parameters as described here
- Start execution of the new kernel
Note that you can define the root filesystem of a kernel using root=[device] boot parameter. You can also change the init program executed by the kernel with init=[pgm] parameter if you don't want to execute the default one /sbin/init.
You can choose to use a new kernel binary for crashdump or simply to use the same one. When you have chosen which kernel, devicetree and root partition to use, you can use kexec utility to construct a crashdump image and load it in the dedicated memory:
BOOTARGS="maxcpus=1 reset_devices earlyprintk root=[root partition] init=[your init]"
kexec --type zImage -p [zImage_file] --dtb=[dtb_file] --append="${BOOTARGS}"Note that you may want to add additional boot parameter depending on your platform. The current boot parameter of a running kernel can be seen in /proc/cmdline.
Then you can simulate a real kernel crash using sysrq (if it is enabled in your kernel):
echo c > /proc/sysrq-triggerYou can either boot on a complete system with a real init like busybox, systemd, SysV or use a minimalist init program which only perform what you want (like in initrd). To test your backup procedure, you can even spawn a shell using init=/bin/sh if there is one in your root partition. Note that there are some limitation in this second system:
- Memory is limited by the amount of RAM you have reserved using the
crashkernelboot parameter of the first Linux. During my tests, I used 64M but it depends on your needs. - You only have one CPU core enabled with boot parameter
maxcpus=1 - Due to small amount of RAM, be carefull not to trigger the OOM Killer !
You can do anything needed to backup the vmcore file on your physical persistent storage which can be anything supported by your Linux kernel (eMMC, MTDs, HDD, ...). Here is a sample script to mount a partition and backup the file in it:
mount -t proc proc /proc
mount -t [fstype] /dev/[device] /debug
dd if=/proc/vmcore of=/debug/vmcore bs=1M conv=fsync
umount /debug
syncNote that conv=fsync prevents from buffering which could lead to OOM triggers as there is not a lot of RAM available.
Using the vmcore file
Once you have saved your vmcore file, you can investigate on what happened in the crashed system and try to find the root cause of your problem.
The easiest-to-use utility I found is crash. See the github and the documentation.
Be careful to use a compiled version compatible with your architecture. If you want to build it from source:
git clone https://github.com/crash-utility/crash.git
cd crash
make target=[your target architecture]In order to use the crash utility, you have to provide the vmlinux file corresponding to kernel used during the crash (the one of the nominal system). Generally, embedded systems use zImage format, so you will also need to keep the vmlinux version of that kernel at compilation time.
Then, to use crash, just launch it with your vmlinux and your vmcore:
$ ~/tools/crash/crash vmlinux vmcore
KERNEL: vmlinux
DUMPFILE: vmcore
CPUS: 2 [OFFLINE: 1]
PANIC: "sysrq: SysRq: Trigger a crash"You will get a lot of useful information. Here is a list of command you can use to do offline debugging:
log: extract the kernel log bufferbt: show the backtracerd [addr]: read memory at the given addressps: extract the process list when the crash occurs
You can also use the help command for complete list:
crash> help
* extend log rd task
alias files mach repeat timer
ascii foreach mod runq tree
bpf fuser mount search union
bt gdb net set vm
btop help p sig vtop
dev ipcs ps struct waitq
dis irq pte swap whatis
eval kmem ptob sym wr
exit list ptov sys q Conclusion
This article has presented one solution to backup crashed product memory before rebooting. This can be useful for unstable products which are already deployed. Among all listed solutions, the kexec one is hardware-agnostic and should be usable with not-too-old kernels on various architecture (tested on ARMv7).
However there are two impacts on runtime when loading a crashdump image:
- You have to reserve a small amount of RAM so there is less for the nominal system
- Rebooting after a crash may take some time if you write lots of data in slow persistent storage. Adding to the downtime of the product.
The crashdump image of kexec is meant to boot a new system when the first one crashes. There are a lot of possible usecases using this feature, not only to backup debugging data.
References
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/kernel_administration_guide/kernel_crash_dump_guide
- https://events.static.linuxfound.org/slides/2011/linuxcon-japan/lcj2011_wang.pdf
- http://lse.sourceforge.net/kdump/documentation/ols2oo5-kdump-paper.pdf
- https://wiki.archlinux.org/index.php/kexec
- https://help.ubuntu.com/lts/serverguide/kernel-crash-dump.html