But de l’article :
Cet article a pour but de présenter une méthode d’allocation mémoire contiguë, utile à certains types de périphériques cherchant à lire directement en mémoire, sans intervention particulière du CPU. Organisé sous la forme d’un tutoriel de construction d’un module Linux, nous y parlerons du DMA et de son implémentation dans Linux. Tout le code présenté ici pourra être retrouvé sur ce dépôt.
Plutôt que de détailler l’ensemble des briques techniques du DMA, déjà largement couverts par la documentation, cet article se concentrera exclusivement sur la problématique de réservation mémoire, le cas d’usage choisi n’ayant pas d’utilité pour toutes les autres fonctionnalités.
Le but de l’article est de donner une base rapide pour intégrer l’allocation cohérente dans un module, présenter quelques problématiques possibles qu’un développeur pourrait rencontrer et montrer l’utilité de l’API DMA dans un cas d’usage concret, bien que pas forcément classique.
Introduction :
Qu’est-ce que le DMA ?
Le DMA (Direct Memory Access) est un procédé consistant à copier des données entre deux adresses mémoires, l’une d’elles correspondant souvent à un périphérique. Ce transfert de données est géré par des contrôleurs DMA, des périphériques auxiliaires dédiés permettant au CPU de réaliser d’autres traitements pendant que le transfert se complète. De cette manière, le DMA permet une réelle parallélisation de ces copies, contrairement à ses alternatives gourmandes en cycles d’horloges CPU : par interruption ou polling. La méthode avec DMA ne fait en réalité travailler le CPU qu’à l’initialisation du transfert et à sa fin.
Ce procédé est extrêmement utile dans certains cas d’usage touchant au traitement de la vidéo ou du son par exemple, les transferts de données y étant souvent volumineux et contraints d’être réalisés à des fréquences élevées, l’utilisation du DMA peut grandement aider ici à augmenter les performances du système en termes de latence comme d’utilisation du CPU. Ses avantages l’ont amené à devenir un standard depuis des décennies.
Ce procédé est configuré informatiquement par un jeu de registres en mémoire. Cette configuration permets d’indiquer au périphérique DMA plusieurs informations importantes sur le transfert mis en place :
- Les adresses source et destination utilisées pour le transfert
- L’appartenance de ces adresses à des périphériques ou des zones mémoire. Cela va changer le comportement du DMA au niveau de l’incrémentation mémoire. Lire une zone mémoire nécessitera cette incrémentation, tandis que la lecture de la FIFO d’un périphérique non.
- La taille de la zone à lire, la taille d’un élément à transférer.
- Enfin, un ensemble d’autres éléments de configuration comme le sens du transfert, sa condition de déclenchement et l’activation d’éventuelles interruptions une fois terminé.
Certains contrôleurs DMA relativement simples ont des besoins spécifiques en termes de mémoire, qui doit pouvoir être intégralement lue par simple incrémentation d’adresses physiques. La continuité physique des données est donc une condition essentielle à leur fonctionnement.
DMA dans linux
Dans tout système d'exploitation, plus le temps passe après le boot, plus la mémoire a tendance à être fragmentée. Cette fragmentation pose un problème lorsque le besoin de grand buffer continu apparaît, ce qui est typiquement le cas de certains contrôleurs DMA.
Pour simplifier l’usage du DMA, le noyau Linux implémente un ensemble de drivers et une API pour les développeurs de drivers. Celle-ci permet de configurer les contrôleurs DMA pour initier un transfert et implémente des méthodes d’allocations mémoires dynamiques capables de répondre à la problématique présentée plus haut.
Cette API se trouve dans plusieurs fichiers : <linux/dma_mapping.h> pour ce qui touche à l’allocation de larges zone mémoire et <linux/dmapool.h> pour des méthodes optimisées pour l’allocation de petits buffers contiguës (inférieur à la taille de page). Nous allons par la suite nous concentrer sur le premier de ces fichiers où nous allons trouver la méthode d’allocation qui nous intéresse : dma_alloc_coherent.
Nous allons voir dans cet article comment utiliser cette méthode dans un module et montrer la capacité des zones mémoire obtenues à être directement utilisées comme tampons DMA par d’autres blocs matériels, ce qui permettra à ces périphériques d’initier des transferts eux-mêmes vers ces zones.
Création d’un module utilitaire :
Choisissons un cas d’usage pour notre module d’allocation. Il nous servira de fil rouge au cours du développement de notre exemple. Prenons un système Linux, tournant sur un processeur que l’on veut faire communiquer avec un périphérique au moyen du DMA.
Posons que c’est le périphérique qui sera le maître du transfert. C’est lui qui contrôle la copie et, par conséquent, nous allons devoir allouer du côté Linux une zone mémoire continue et lui communiquer l’adresse physique de celle-ci.
Afin d’éviter les soucis d’accès concurrents, de synchronisation et autres problématiques typiques des systèmes multiprocesseur, nous allons faire en sorte que le transfert ne se lance qu’après réception de l’adresse physique de l'espace mémoire par notre périphérique et n’allons lire notre espace de donnée qu’après réception d’une forme d’acquittement de l’écriture.
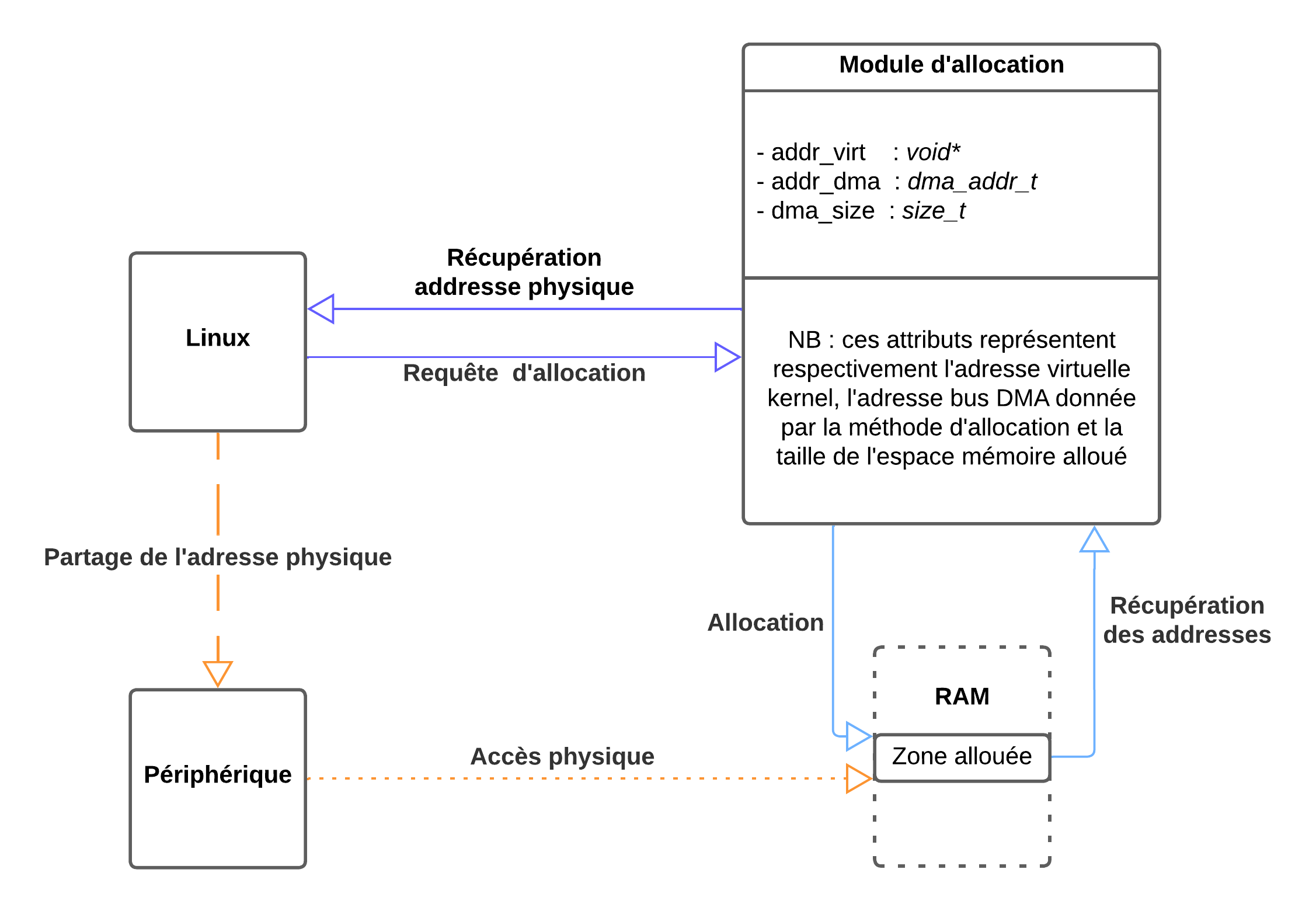
Notre périphérique ne gérant que de la mémoire physique continue, nous allons avoir besoin :
- D’allouer une zone mémoire contiguë, non-cacheable et non-bufferisable.
- De récupérer l’adresse physique et de la rendre disponible à l’espace utilisateur pour simplifier l’exemple.
- De trouver un moyen de communiquer avec notre périphérique pour lui transmettre cette adresse physique. Ici, nous ne nous concentrerons pas sur ce point, plusieurs solutions sont disponibles.
Demander que notre données soit non-cacheable et non bufferisable nous garantit qu’il n’existe aucune donnée en attente dans une zone tampon ou stockée dans les caches de notre processeur. On évite ainsi certaines problématiques d’incohérence voire de corruption mémoire.
Comme le "coherent" dans son nom l'indique, ce sont heureusement deux caractéristiques que nous garantit dma_alloc_coherent.
Initialisation du module
Commençons par la base : l’implémentation d’un module qui va pouvoir être inséré et retiré librement du noyau.
#include <linux/module.h> // Pour le squelette du module
#include <linux/init.h>
#include <linux/dma-mapping.h> // Pour les fonctionnalités d'allocation
#include <linux/dma-direct.h>
#include <linux/kernel.h> // Pour l'interaction utilisateur (dans l'exemple)
#include <linux/sysfs.h>
#include <linux/kobject.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Tom Humbertclaude");
MODULE_DESCRIPTION("Allocates DMA coherent memory address for external audio use");
#define DEVICE_NAME "my_dma_allocator"
static dev_t dev_num;
static struct class *my_class;
static struct device *my_device;
static int __init my_dma_allocator_init(void) {
int ret;
ret = alloc_chrdev_region(&dev_num, 0, 1, DEVICE_NAME);
if (ret)
return ret;
my_class = class_create(THIS_MODULE, DEVICE_NAME);
if (IS_ERR(my_class))
return PTR_ERR(my_class);
my_device = device_create(my_class, NULL, dev_num, NULL, DEVICE_NAME);
if (IS_ERR(my_device)) {
ret = PTR_ERR(my_device);
goto destroy_class;
}
return 0;
destroy_class:
class_destroy(my_class);
unregister_chrdev_region(dev_num, 1);
return ret;
}
static void __exit my_dma_allocator_exit(void) {
device_destroy(my_class, dev_num);
class_destroy(my_class);
unregister_chrdev_region(dev_num, 1);
}
module_init(my_dma_allocator_init);
module_exit(my_dma_allocator_exit);Ce code réalise trois choses dans son initialisation (fonction "init") :
- Réserve un numéro majeur/mineur.
- Crée une classe au nom de notre module, visible dans /sys/class/ qui contient des informations générales sur notre module et qui permettra de simplifier la procédure de création du device.
- À l’aide de cette classe, crée un "device node" visible dans /dev/. Ce fichier sera notre point d’entrée du côté utilisateur, c’est celui qui nous permettra d’interagir avec ce module.
La fonction "exit" quant à elle libère toutes les ressources allouées et détruit le device.
Le module plus haut est donc un code exemple minimal qui compile, crée toutes les ressources nécessaires à notre cas d’usage et peut être inséré dans l'espace mémoire du noyau Linux, bien qu’il ne fasse pas grand-chose actuellement… Donnons-lui donc un peu d’utilité !
Allocation DMA
Nous allons déjà faire en sorte de pouvoir allouer notre premier buffer DMA contiguë depuis ce module. L’API DMA rend ceci plutôt simple, elle s’inclut avec :
#include <linux/dma-mapping.h>
Et devrait nous permettre d’obtenir notre zone mémoire avec la fonction :
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, gfp_t gfp);Cette fonction retourne l’adresse virtuelle et prend en paramètre :
- La structure device que nous venons de créer.
- La taille en octets de la zone mémoire à allouer, similaire à un simple kmalloc.
- Un pointeur vers un dma_addr_t, un type permettant de contenir les adresses bus des zones allouées par DMA et servant de handle pour le reste des fonctionnalités de l’API.
- Des flags d’allocation, permettant de définir les zones mémoires à considérer pour l’allocation et spécifier la synchronicité de l’opération.
Ce dernier paramètre permet d’appliquer des filtres sur le type de mémoire qui va être utilisé pour l’allocation. Par exemple le flag __GFP_RECLAIM, permet d’indiquer à l’allocateur qu’il a le droit d’aller chercher son espace mémoire dans des zones dont le contenu a été marqué comme déplaçable. C'est à dire que ces contenus peuvent être déplacés physiquement dans la mémoire sans que cela influe sur les adresses virtuelles pointant sur eux. On peut donc les bouger sans craindre d'erreurs des processus les utilisant.
Nous souhaitons dans notre cas maximiser les chances de réussite de nos allocations, surtout si nous cherchons à réserver une grande plage de données, en permettant à l’API DMA d’utiliser le CMA (Contiguous Memory Allocator).
Cet allocateur particulier a été créé pour répondre à la difficulté de réserver de grands espaces mémoire physiquement continus sur des systèmes fragmentés. Il fonctionne en réservant au moment du boot un grand espace mémoire contigu, en modifiant ses caractéristiques pour qu’il n’accepte que des données de cache ou déplaçables. Ainsi, en appelant cet allocateur, on cherche tout simplement le premier bloc libre de sa zone mémoire respectant les contraintes et le réserve quitte à déplacer ou supprimer les données qui gênent.
Cette méthode d’allocation n’est pas atomique et nécessite potentiellement plusieurs étapes de réclamation mémoire avant de réussir. L’implémentation nous interdit donc certains flags comme GFP_ATOMIC.
Nous allons ici utiliser GFP_KERNEL pour nos flags. Il contient le flag de réclamation et ne contient pas ceux incompatibles avec l’utilisation du CMA. Ceci nous permettra donc de viser des allocations de plus de quelques pages contiguës en réduisant grandement les risques d’échecs.
Créons donc une petite structure capable d’accueillir les informations de notre buffer :
struct my_buffer_s{
void* addr_virt;
dma_addr_t addr_dma;
size_t dma_size;
};
static struct my_buffer_s my_buffer;
Créons également une fonction d’allocation, qui se charge de mettre à jour ces données une fois l’allocation faite. Nous préférons ici allouer une taille alignée sur la taille des pages systèmes pour plusieurs raisons :
Certains appels systèmes et fonctions nécessitent des adresses alignées sur les pages systèmes. C’est le cas notamment de certaines fonctions de mapping ou de protection de zone mémoire.
Par sécurité, dans le cas de l’utilisation de telles fonctions, nous pouvons garantir que les pages manipulées au cours de leur exécution ne peuvent pas être mélangées avec des adresses non valides ou appartenant à un autre bloc mémoire.
De manière générale, adopter une stratégie d’allocation “au moins égale” et alignée sur les tailles de pages est une bonne pratique.
static long my_dma_alloc(size_t size) {
dma_addr_t _addr_dma;
if (my_buffer.addr_virt) {
my_dma_free();
}
my_buffer.addr_virt = dma_alloc_coherent( my_device,
PAGE_ALIGN(size),
&_addr_dma,
GFP_KERNEL);
if (!my_buffer.addr_virt) {
pr_err("dma_alloc_coherent failed\n");
return -ENOMEM;
}
my_buffer.dma_size = PAGE_ALIGN(size);
my_buffer.addr_dma = _addr_dma;
return 0;
}
Il nous reste désormais à ajouter un appel à cette fonction à la fin de la fonction d'initialisation pour la lancer directement à l’insertion du module et on obtient :
[23876.105478] dma_alloc_coherent failed
***Ouch***
La trace complète est bien plus longue et, bien heureusement, nous annonce ce qui ne va pas. À moins d’une heureuse configuration par défaut qui empêche cette erreur, le problème est annoncé au tout début :
WARNING: CPU: 0 PID: 680 at kernel/dma/mapping.c:494 dma_alloc_attrs+0xbc/0xf0
Rechercher dans les sources du noyau permet de trouver cette ligne 494 et ce qui ne va pas :
WARN_ON_ONCE(!dev->coherent_dma_mask);
Il semblerait qu’il manque un élément de configuration à notre structure device ! Un élément plutôt important en réalité : le coherent_dma_mask. Ce masque permet de définir jusqu'à quelle adresse un périphérique DMA est capable d’adresser.
Sur notre périphérique, le contrôleur DMA ne peut prendre en charge que des adresses 32 bits, la fonction demande donc de lui indiquer cette limitation dans le device. La documentation indique que même si les paramètres par défaut du système permettent de faire des allocations sans toucher à ce masque, cela reste une bonne pratique de le définir pour une meilleure portabilité et de manière générale pour montrer que l’on sait ce qu’on fait. Nous pourrions mettre cette valeur à jour nous même, mais l’API DMA permet de le faire de manière fonctionnelle :
int dma_set_coherent_mask(struct device *dev, u64 mask);
u64 dma_get_required_mask(struct device *dev);
Bien sympathiquement, l’API nous permet aussi de récupérer le masque adapté à notre système. L’information est extraite des attributs dma-ranges provenant du device tree ou calculée à partir du nombre de pages physiques total détecté sur le système.
Ajoutons donc ces lignes à notre fonction d' initialisation, avant toute tentative d’allocation :
ret = dma_set_coherent_mask(my_device,dma_get_required_mask(my_device));
if (ret)
goto destroy_device; //Gestion d'erreur, cf annexe pour précisionATTENTION : bien que ces deux fonctions s'imbriquent de manière plutôt satisfaisante, un système mal configuré pourrait empêcher dma_get_required_mask de retourner un masque valide et donc provoquer une erreur. Il est possible aussi en se renseignant sur les limites d'adressage de son système de donner directement un masque par la macro DMA_BIT_MASK(32), pour un masque 32 bits par exemple.
Recompilons, relançons et, avec un petit affichage d’information, on obtient :
[ 3166.752926] DMA virt addr: ffff80000be51000
[ 3166.752926] DMA phys addr: 00000000a2300000
[ 3166.752926] Size: 1048576
Victoire ! Nous avons un bloc mémoire contigu alloué ! Le libérer ne devrait pas poser problème ici, pourvu que nous appelions la bonne fonction :
void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t dma_handle);
Je l’enveloppe ici dans mon module d’une petite fonction utilitaire pour mettre à jour ma structure de donnée :
static void my_dma_free(void) {
if (!my_buffer.addr_virt)
return;
dma_free_coherent(my_device, my_buffer.dma_size, my_buffer.addr_virt, my_buffer.addr_dma);
memset(&my_buffer, 0, sizeof(my_buffer));
}Et voilà notre module capable de réaliser une allocation. Pour compléter mon exemple, je vais vouloir être capable de lui donner un ordre d’allocation depuis le user space et montrer qu’un transfert DMA est possible vers cette zone mémoire.
Ajout de sysfs
Le périphérique imaginaire qui contrôle le DMA est relativement simple et se contente de recevoir l’adresse physique et la taille du buffer alloué pour entamer un transfert vers celui-ci, nous lui écrirons ce message depuis l'espace utilisateur.
Dit autrement : le module que nous sommes en train d’écrire doit être capable d’exporter la taille et l’adresse physique du buffer alloué vers l’espace utilisateur. Une manière de permettre l’interaction de l’espace utilisateur avec le module est de créer des fichiers dans sysfs permettant d’implémenter des comportements spécifiques à leur lecture ou écriture.
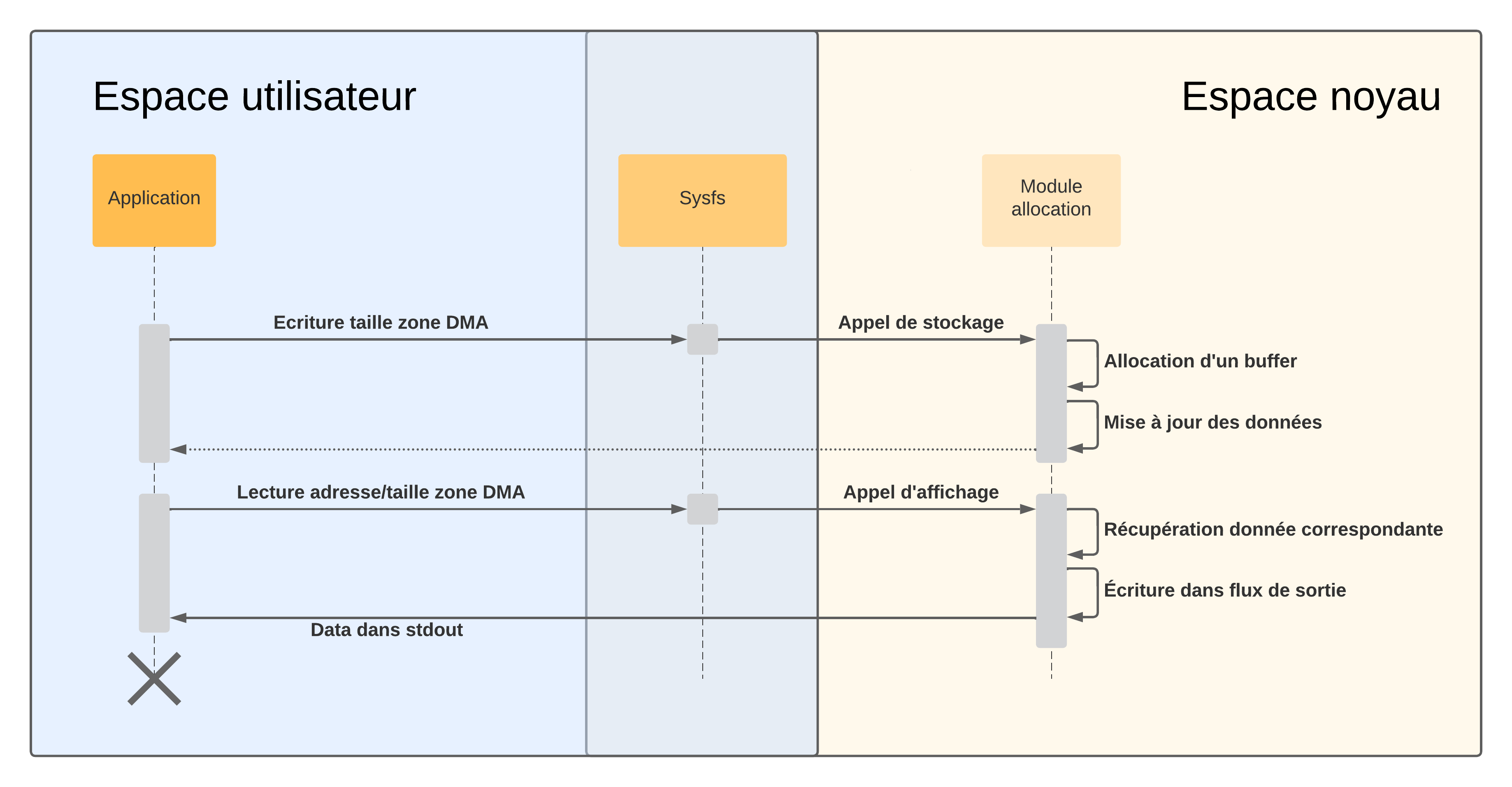
Nous allons ici permettre à notre utilisateur de lire la valeur de l’adresse physique du buffer actuel et sa taille. Nous allons également lui permettre de contrôler la taille du buffer en question en écrivant directement dans le fichier correspondant. Petit disclaimer : l'exposition d'adresses physiques à l'espace utilisateur est généralement considérée comme une mauvaise pratique, je ne le fais ici que par simplicité et volonté de laisser le module aussi minimal que possible.
Cela implique tout d’abord d’implémenter les fonctions d’affichage et de stockage (répondant respectivement aux requêtes de lecture et d’écriture) de nos fichiers :
static ssize_t addr_phys_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf) {
return sprintf(buf, "%llx\n", dma_to_phys(my_device, my_buffer.addr_dma));
}
static ssize_t dma_size_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf) {
return sprintf(buf, "%ld\n", my_buffer.dma_size);
}
static ssize_t dma_size_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t count) {
size_t size = 0;
if (kstrtoul(buf, 10, &size))
return -1;
if (size) {
my_dma_alloc(size);
}
else {
my_dma_free();
}
return count;
}
Ce n'est pas directement l’adresse bus de type dma_addr_t que nous voulons remonter mais bien l’adresse physique réelle, d’où l'utilisation d'une méthode nommée dma_to_phys, qui nous permet de faire exactement cette traduction.
Les affichages se contentent de réaliser un affichage de la variable correspondante, tandis que l’écriture de la taille du buffer provoque une libération ou une ré-allocation. La création des fichiers nécessitent des attributs générés de la manière suivante :
static struct kobj_attribute addr_phys_attr = __ATTR_RO(addr_phys); // Read-Only
static struct kobj_attribute dma_size_attr = __ATTR_RW(dma_size); // Read-WriteCes macros prennent un NOM en paramètre et décrivent une structure de données contenant le NOM, une méthode "show", par défaut nommée <NOM>_show, une méthode "store" nommée <NOM>_store et un mode d’accès selon les autorisations spécifiées.
Vient le moment de créer notre dossier depuis l’init dans l'arborescence /sys/kernel/ avec :
static struct kobject *my_kobj;
my_kobj = kobject_create_and_add(DEVICE_NAME, kernel_kobj);
if (IS_ERR(my_kobj))
return PTR_ERR(my_kobj);Et enfin y ajouter nos fichiers avec :
long ret;
ret = sysfs_create_file(my_kobj, &addr_phys_attr.attr);
if (ret)
goto rm_kobj;
ret = sysfs_create_file(my_kobj, &dma_size_attr.attr);
if (ret)
goto rm_first_sysfs;Une fois recompilé et le module réinséré, nous pouvons vérifier notre travail :
# ls -la /sys/kernel/my_dma_allocator/
drwxr-xr-x 2 root root 0 Jun 12 20:25 .
drwxr-xr-x 15 root root 0 Jan 1 1970 ..
-r--r--r-- 1 root root 4096 Jun 12 20:25 addr_phys
-rw-r--r-- 1 root root 4096 Jun 12 20:25 dma_sizeLes fichiers s’y trouvent bien et nos variables sont accessibles. Le contrôle de l'allocation se fait désormais à partir d’une simple écriture dans dma_size. Partageons désormais ces données à notre périphérique et voyons ce qui arrive !
Nous allons utiliser ici un microcontrôleur auxiliaire pour initier un transfert DMA vers cette zone mémoire, avant d’afficher son contenu pour vérification. Ce transfert servira à remplir le buffer d’un "Lorem Ipsum", ce qui permettra de vérifier l’allocation correcte de la mémoire, et le bon alignement entre l’adresse virtuelle kernel et la physique. Cet exemple nécessite donc deux blocs MPU et MCU contenu dans le même SoC, nous le faisons tourner ici sur un iMX8DX.
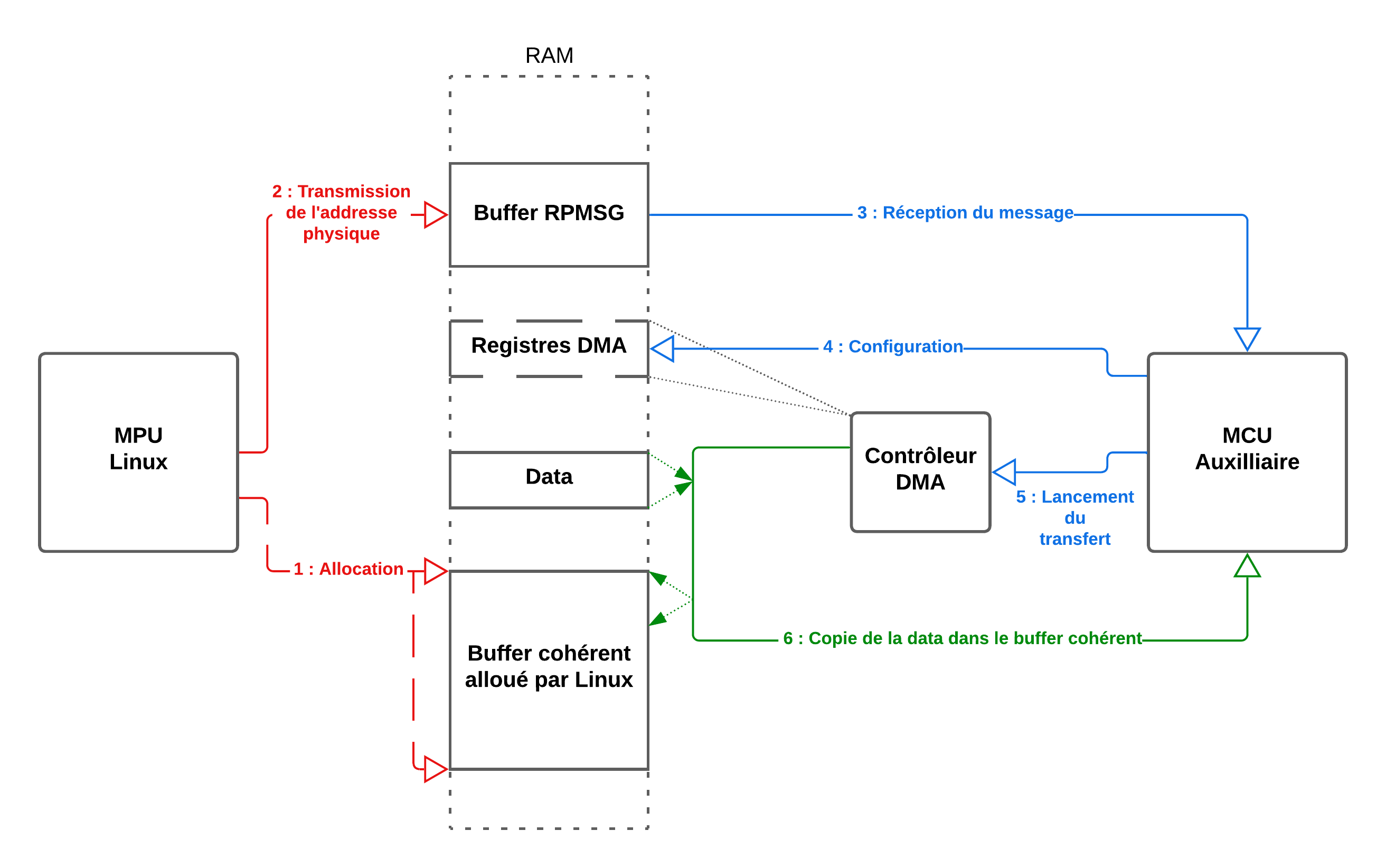
Le code côté microcontrôleur est ici extrêmement dépendant du hardware, et ne se trouvera donc pas dans cet article. En revanche, pour quiconque souhaiterait le reproduire, le firmware se base sur l’exemple multicœur rpmsg_lite_str_echo_rtos du SDK MCUXpresso , légèrement modifié pour lire l’adresse dans le message entrant, et utilise le driver imx_tty_rpmsg côté Linux.
Côté Linux cela donne :
Found dma allocator device
[ 17.471864] DMA virt addr: ffff800009f0b000
[ 17.471864] DMA phys addr: 83cd7000
[ 17.471864] Size: 4096
Allocation done
Found physical adress : 83cd7000
Write done !
Waiting for 10s ...
[ 27.489883] Freed DMA region
DONELes fichiers sysfs sont trouvés, l’allocation se fait bien et la libération aussi, aucun soucis de ce côté-là, voyons du côté du microcontrôleur :
RPMSG String Echo FreeRTOS RTOS API Demo...
Nameservice sent, ready for incoming messages...
Get Greetings From Master Side : "hello world!" [len : 12]
Get Message From Master Side : "83cd7000 4096" [len : 13]
GOT VAR : 83CD7000 4096
Transfert done !
Reading in 3...2...1...
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vestibulum et ultrices odio. Suspendisse [...]Le Lorem Ipsum a bien été trouvé, et tout parait cohérent, victoire !
Conclusion :
Nous avons appris ici à allouer un espace cohérent pour une utilisation audio depuis un module Linux, espace qui pourra être la cible d’un transfert DMA initié par nos périphériques. Nous avons également vu une méthode pour rendre l’allocation contrôlable par l’espace utilisateur au travers du sysfs.
En conclusion, le driver DMA fournit une API plutôt simple d’usage permettant de créer des modules d’allocations, voire de transfert de données rapidement et efficacement.
Il faut cependant retenir que ni le cas d’usage ni la réponse proposée dans ce tutoriel n’est parfait. Rien ne garantit par exemple que de l’espace suffisant à une allocation est disponible à un instant donné, et donc rien ne garantit que dma_alloc_coherent fonctionne. Le dynamisme a ses avantages, mais il faut garder ses défauts en mémoire. Les systèmes critiques ne devraient pas se baser là-dessus, ou tout du moins préparer des sécurités en cas d’échec, que je ne montre aucunement ici.
Cet article est donc une invitation pour le lecteur à découvrir plus en détails la documentation de l’API DMA pour comprendre comment intégrer au mieux cette API à son projet et découvrir les fonctionnalités de transferts depuis Linux, qui n’ont pas été présentées ici.
NB :
Certains systèmes intègrent des IOMMU, des composants permettant la virtualisation des adresses physiques pour les périphériques DMA. Ces composants sont utilisés pour sécuriser les zones mémoires des périphériques et permettent de contourner les problématiques de fragmentation mentionnées au cours de cet article.
Dans un système utilisant ces composants, le cas d’usage proposé ici n'est pas adapté. Notre fonction d’allocation nous retournera une IOVA (IO Virtual Address) en troisième paramètre et les problématiques d’accès mémoire partagées deviennent très différentes.
Ce cas d’usage particulier dépasse le cadre de cet article, mais pourrait faire l’objet d’un autre ultérieurement.
Références :
https://www.kernel.org/doc/Documentation/DMA-API.txt
https://docs.kernel.org/core-api/dma-api-howto.html
https://lwn.net/Articles/486301/
https://lwn.net/Articles/1016844/
https://www.xml.com/ldd/chapter/book/ch13.html