Linux est un système d’exploitation préemptif offrant des interfaces très riches pour bien ordonnancer, synchroniser et contrôler l’affinité de chaque processus (ou thread) utilisateur.
En effet, les fonctionnalités temps réel déja disponibles sous Linux vanilla (appelé aussi Linux standard) sont généralement largement suffisantes pour répondre à nos besoins temps réel souple et applications industrielles non critiques.
Echéances des tâches et sources de non-déterminisme sous Linux
Le déterminisme est la capacité d'un système à répondre à un événement avant qu'un certain temps limite (appelé l'échéance) ne soit écoulé. En pratique, Linux Vanilla peut assurer l'exécution de la majorité des tâches avant leur échéance.
Pour comprendre et mettre en place une solution Linux temps réel souple, il faut comprendre les sources de non-déterminisme.
Plusieurs raisons peuvent être à l’origine de la non garantie de l'exécution des tâches avant échéance et empêcher un système de remplir les prérequis temps réel. Parmi celles ci, nous pouvons citer les plus importantes :
- La politique d'ordonnancement : la capacité de l’ordonnanceur à choisir la prochaine tâche à exécuter en tenant compte des priorités et des échéances est la partie la plus cruciale ; elle est souvent la source de la majorité des latences dans les systèmes temps réel.
- La migration de tâches : l’exécution d’une tâche sur un autre processeur (que celui sur lequel elle a été lancée la première fois) introduit des pénalités dans le temps d’exécution et surtout constitue une source de non-déterminisme.
- Les défauts de page : les OS modernes (et Linux en particulier) appliquent plusieurs optimisations comme le « lazy loading » ou encore le « Copy on write », ce qui fait que dans certains cas une page mémoire va être chargée (de la mémoire virtuelle vers la mémoire physique) seulement lorsque l’utilisateur y fait appel. Souvent on compare un espace de mémoire virtuelle à un contrat signé entre le processus et l’OS, et la mémoire physique à ce que l’OS a vraiment respecté dans les termes du contrat. La solution consiste à verrouiller ces pages (avec la fonction
mlock()oumlockall()) comme le montre mon collègue Vincent dans son article : https://www.linuxembedded.fr/2020/01/overcommit-memory-in-linux/. - Préemption du noyau : ce paramètre dépend fortement de la manière dont le noyau a été compilé. Cette option désigne la possibilité d’arrêter temporairement du code s’exécutant dans le noyau en faveur d’une tâche utilisateur plus prioritaire qui vient de se réveiller. Cette fonctionnalité est apparue à partir de Linux 2.6 (auparavant, il était impossible de préempter une tâche s’exécutant en mode noyau jusqu’à l’accomplissement du traitement et le retour vers l’espace utilisateur où l’ordonnanceur était appelé) et définit 3 niveaux de préemption comme ceci :
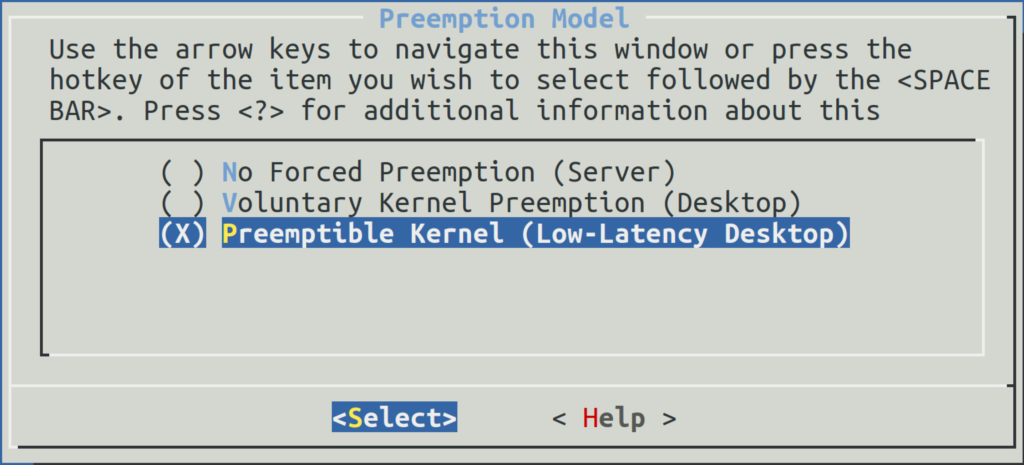
- No Forced Preemption (Server) : le noyau n’est pas préemptif. Ce mode est utilisé pour les serveurs et les machines orientées vers le calcul scientifique.
- Voluntary Kernel Preemption (Desktop) : le code noyau est préempté principalement sur les routines jugées longues (en ajoutant des points de préemption). Ce mode est préconisé pour les machines avec peu de périphériques.
- Preemptible Kernel (Low-Latency Desktop) : Cette option rend pratiquement tout le code kernel préemptible à l’exception des accès aux sections critiques. Les systèmes embarqués temps réel souple doivent utiliser cette option.
Linux Preempt-RT va encore plus loin en optimisant les temps d’accès aux ressources concurrentes (avec une pénalité d’overhead). Un article bien détaillé élaboré par mon collègue Robin est disponible sur : https://www.linuxembedded.fr/2019/09/le-temps-reel-sous-linux/
- Les inversions de priorités : Dans un système qui contient au minimum 3 tâches, une tâche de haute priorité peut attendre longtemps (ou même indéfiniment) une tâche moins prioritaire préemptée par une tâche d’une priorité intermédiaire. Linux implémente déjà l’héritage de priorité pour éviter ce genre de situation.
Dans cet article nous allons nous concentrer sur la politique d’ordonnancement, de la migration des tâches et aussi la manière de booster les performances des CPU pour réduire le risque de rater les échéances.
Politiques d'ordonnancement sous Linux
Il est possible de regrouper la politique d'ordonnancement en 2 catégories :
- Temps partagés (priorité statique 0) : c’est le mode par défaut. les processus sont assignés à une priorité 0. C’est dans ce cas que l’ordonnanceur doit prendre les décisions les plus pertinentes pour sélectionner la prochaine tâche à exécuter.
- Temps réel souple (priorités statiques [1-99]) : l’intervalle de priorité [1-99] est réservé pour les processus temps réel. L’ordonnanceur choisira toujours le processus temps réel avec la plus haute priorité qui souhaite s'exécuter.
Ordonnancement à temps partagés
Par défaut, tous les processus sont soumis à une politique d’ordonnancement à temps partagés (appelé aussi priorité 0). Depuis Linux 2.6.23, CFS, Completely Fair Scheduler en anglais, est le nom de l’ordonnanceur qui s’occupe de ce mode.
Le CFS applique une méthode d’équité pour s’assurer que chaque processus bénéficie d’une partie du temps CPU selon ses besoins. Le scheduler utilise un arbre binaire « rouge et noir » et applique un algorithme de telle sorte que le processus qui a bénéficié du moins de temps CPU apparaît en bas à gauche de l’arbre. Ce dernier est directement envoyé pour exécution.
Ce mode temps partagés se décompose en 3 politiques d’ordonnancement :
- SCHED_NORMAL, appelé aussi SCHED_OTHER : c’est la politique par défaut.
- SCHED_BATCH : même politique d'ordonnancement que SCHED_NORMAL, à la différence que les processus bénéficient de plus longues périodes d’exécution et doivent donc attendre plus longtemps pour être réexécutés.
- SCHED_IDLE : En l’absence de tâches SCHED_NORMAL et SCHED_BATCH à exécuter, les threads de cette politique seront sélectionnés pour exécution. Ce groupe de threads possède la priorité la plus faible sous Linux.
N.B : Linux favorise SCHED_NORMAL (I/O bound) par rapport à SCHED_BATCH (CPU bound).
Géstion de la politique d'ordonnancement partagée
Linux dispose des interfaces requises permettant de manipuler les politiques déja abordées.
Le header "sched.h" définit les fonctions suivantes :
- int sched_getscheduler(pid_t pid) : renvoie la politique d'ordonnancement.
- int sched_setscheduler(pid_t pid, int policy, const struct sched_param *param) : pour attribuer une politique d'ordonnancement.
Pour mieux comprendre ces deux fonctions, nous allons prendre un simple exemple qui affiche et modifie la politique d'ordonnancement d'un processus :
#define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sched.h> #include <errno.h> void display_process_sched_attributes(){ /* * Retourne la politique d'ordonnacement * du procesus en cours. */ int scheduler_policy = sched_getscheduler(0); printf("Current scheduling policy : "); switch(scheduler_policy){ case SCHED_OTHER: printf("SCHED_OTHER\n"); break; case SCHED_BATCH: printf("SCHED_BATCH\n"); break; case SCHED_IDLE: printf("SCHED_IDLE\n"); break; case -1: perror("sched_getscheduler error"); break; /* * Il existe 2 autres politiques, SCHED_FIFO * et SCHED_RR, réservées au temps réel. */ default: printf("Unknown\n"); break; } } int main(int argc, char *argv[]){ struct sched_param sched_p; /* Affiche la politique d'ordonnancement. */ display_process_sched_attributes(); /* * sched_priority est le seul champs * de paramètrage d'ordonnancement (de la structure * sched_param) garantie d'être supporté par Linux. */ sched_p.sched_priority = 0; // Pas prise en compte dans le temps partagé /* * sched_setscheduler change la politique d'ordonnancement. * 1er param : PID du processus (0 pour processus en cours). * 2ème param : type de politique d'ordonnancement * 3ème param : paramètre d'ordonnancement. */ if(sched_setscheduler(0, SCHED_BATCH, &sched_p) == -1) perror ("sched_setscheduler "); display_process_sched_attributes(); return EXIT_SUCCESS; }
à l'exécution :

La valeur nice
Il existe une métrique capable d'influencer le CFS pour choisir certains processus plutôt que d’autres, cette dernière est connue sous le nom de valeur nice.
La valeur nice est comprise dans l’intervalle [-20, 19] : plus cette valeur est élevée, moins le processus est prioritaire.
La valeur nice peut être manipulée de 2 façons :
- L’interface nice (obsolète) : étant l’ancienne interface définit dans « unistd.h ». Un exemple d'utilisation est illustré ci-dessous :
#include <stdio.h> #include <stdlib.h> #include <unistd.h> // inclure nice(). #include <errno.h> int main(int argc, char *argv[]){ /* * nice altère la priorité dynamique d'un processus * à exécution temps partagés. * param : Nouvelle valeur de nice (0 pour récupérer * la valeur en cours). */ int nice_value = nice(0); printf ("--- Initial nice value %d ---\n", nice_value); /* * Reset de errno avant d'appeler nice. * nice changera cette valeur dans le cas * d'une erreur. */ errno = 0; // Incrémenter la valeur nice à 5 (baisser la priorité dynamique). nice_value = nice(5); /* * La vérification de errno est requise car nice = -1 * représente aussi une valeur valide nice=[-20, 19]. */ if(nice_value == -1 && errno != 0){ perror ("nice error"); } else { printf ("--- New nice value is : %d --\n", nice_value); } return EXIT_SUCCESS; }
Lors de l'exécution du programme, on voit clairement que la valeur de nice a augmenté :

- Interfaces getpriority() et setpriority() : est la solution la plus recommandée (un peu plus complexe de nice).
#include <stdio.h> #include <stdlib.h> #include <sys/time.h> #include <sys/resource.h> // inclure setpriority(), getpriority() #include <errno.h> int process_nice_value = 0; void display_process_nice_value(char *stepName){ // Get current process priority. process_nice_value = getpriority(PRIO_PROCESS, 0); printf ("%s process priority : %d\n", stepName, process_nice_value); } int main(int argc, char *argv[]){ display_process_nice_value("Previous"); errno = 0; /* setpriority modifie la priorité dynamique * d'un processus s'exécutant en politique temps partagée. * PRIO_PROCESS et 0 : appliquer sur le processus en cours. * -10 : nouvelle valeur de nice. */ process_nice_value = setpriority(PRIO_PROCESS, 0, -10); if((process_nice_value == -1) && (errno != 0)){ perror ("setpriority error"); } else { printf("------- Nice Updated --------\n"); } display_process_nice_value("Current"); return EXIT_SUCCESS; }
Lors de l'exécution, il faut disposer des droits "root" pour pouvoir réduire la valeur de nice (un processus non root ne peut qu'augmenter cette dernière) comme le montre l'image suivante :
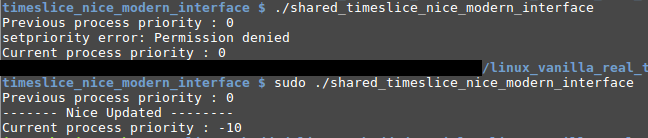
N.B : Si jamais une valeur de nice incorrecte (nice!=[-20, 19]); Linux arrondie silencieusement cette dernière aux bornes de l'intervalle.
A connaître aussi sur nice
L’impact de la valeur nice va au-delà du CFS et affecte aussi l’ordonnanceur I/O qui utilise par défaut la valeur nice d’un processus. Linux propose deux appels système pour changer explicitement le comportement par défaut du scheduler I/O :
- int ioprio_get (int which, int who) : pour récupérer la priorité I/O d’un processus (les paramètres sont similaires à getpriority()).
- int ioprio_set (int which, int who, int ioprio) : pour modificer la priorité I/O d’un processus (les pamètres sont similaires à setpriority()).
Cependant, étant des appels système, ces derniers ne sont pas très portables. Du coté de Glibc, il n’existe pas encore d’interface utilisateur pour gérer la priorité I/O. Le meilleur moyen portable actuellement est l’usage de l’utilitaire ionice.
Ordonnancement temps réel souple
Linux a introduit depuis quelques années la notion de temps réel souple. Contrairement aux temps partagés, priorité statique 0, les processus temps réel peuvent se voir assigner une priorité dans l’intervalle [1-99] ou 99 est la plus haute priorité temps réel sous Linux.
Ce mode de fonctionnement est suffisant pour satisfaire la majorité des échéances du système.
Le mode temps réel supporte plusieurs politiques de fonctionnement:
- SCHED_FIFO : un processus appliquant cette politique va s’exécuter jusqu’à complétion, ou jusqu’à ce qu’il bloque sur un appel système ou se préempte volontairement avec
sched_yield(). Si le système contient plusieurs processus SCHED_FIFO avec la même priorité, c’est la méthode du premier arrivé premier servi qui est appliquée. - SCHED_RR : les processus SCHED_RR, de mêmes priorités, devront prendre à tour de rôle la ressource CPU. Chacun va exécuter le timeslice qui lui a été attribué avant d’être préempté par l’ordonnanceur. Le timeslice est défini et peut-être ajusté dans le fichier /proc/sys/kernel/sched_rr_timeslice_ms. Généralement : la valeur par défaut est 100.
N.B : s'il n'existe qu'un seul processus SCHED_RR, il sera re-sélectionné par le scheduler à chaque expiration de son timeslice.
Exemple : Création processus temps réel
Dans de cet exemple, nous allons comparer l'incrémentation d'un compteur lorsque le processus est en ordonnancement à temps partagé puis lorsqu'il sera mis en temps réel, sur une période de 200 secondes.
Remarque : cette idée a été dérivée du livre de Christophe Blaesse "Solutions temps réel sous Linux".
#define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sched.h> #include <time.h> #include <errno.h> void incrementCounter(char *stepName){ long long int counterLoop = 0; time_t counterStat; time(&counterStat); /* Incrémenter le compteur tant que le processus s'exécute sur le CPU. */ while(time(NULL) < (counterStat + 200)){ counterLoop++; } printf("[%s] => Counter value : %lli\n", stepName, counterLoop); } int main(int argc, char *argv[]){ struct sched_param sched_p; incrementCounter("SCHED_OTHER"); // Création d'un processus temps réel // (priorité statique 70) avec une politique FIFO. sched_p.sched_priority = 70; if(sched_setscheduler(0, SCHED_FIFO, &sched_p) == -1) perror ("sched_setscheduler "); else printf("------ Scheduling policy updated ------\n"); incrementCounter("SCHED_FIFO "); return EXIT_SUCCESS; }
Après l'exécution du programme, il est clair que le compteur a été incrémenté un plus grand nombre de fois dans le mode temps réel (le processus n'ayant pas été interrompu).

Important
Seuls les processus possédant les droits CAP_SYS_NICE, pouvant être accordé par root, peuvent appliquer une politique temps réel.
Affinité des tâches
Les systèmes multi-coeur posent d'avantages de contraintes sur le scheduler. Ce dernier doit faire des choix optimaux non seulement en sélectionnant la prochaine tâche à exécuter (avec les critères vus précédemment) mais également sur quel processeur la faire tourner tout en essayant d’équilibrer la charge des tâches entre les différents processeurs. Ce qui veut dire que l’ordonnanceur doit faire des choix judicieux selon des critères dont le plus important est l’affinité.
L'affinité définit la probabilité qu'une tâche soit réexécutée sur le même processeur que celui sur lequel il a été exécuté la dernière fois.
Plus l'affinité est élevée, moins la tâche migrera et moins il y a de risque de rater les échéances.
On distingue 2 types d'affinités sous Linux que nous allons découvrir dans la prochaine section.
Affinité souple
Lorsque une tâche est exécutée sur un processeur, le scheduler va essayer de la réexécuter toujours sur ce dernier. En effet, la migration de tâches est très coûteuse et pénalise l’utilisateur pour diverses raisons dont la principale est lié au cache.
Dans les machines SMP, chaque processeur possède un cache. Si une tâche déjà exécutée sur le CPU1 doit être migrée vers le CPU2, le cache CPU1 doit être invalidé ; pire encore la tâche ne pourra plus bénéficier de cet ancien cache.
C’est pour cela que, par défaut, le scheduler sous Linux applique ce principe d’affinité.
Cependant, si un processeur est plus chargé qu’un autre, CFS appliquera une migration de tâche. C’est ce qui explique le nom "affinité souple".
Affinité Stricte
Pour les applications temps réel, le comportement par défaut du scheduler est insuffisant car une migration de tâche peut potentiellement augmenter la probabilité de rater les échéances. Linux propose des APIs pour forcer l’affinité d’une tâche sur un processeur dédié. C’est que qu’on appelle l’affinité stricte.
Linux définit les API suivantes pour manipuler l’affinité stricte d'un processus :
- Les processeurs utilisés par un processus (ou un thread en particulier) sont représentés par la structure
cpu_set_tqui définit un masque de bits des processeurs du système. CPU_SETSIZEétant le nombre maximal de processeurs qui peuvent être représenté parcpu_set_t(actuellement :CPU_SETSIZE= 1024).- Et enfin, pour récupérer ou affecter l'affinité à un processus; les interfaces suivantes doivent être utilisées :
int sched_setaffinity (pid_t pid, size_t setsize, const cpu_set_t *set) :pour définir l'affinité d'un processus avec les processeurs définis danscpu_set_t.int sched_getaffinity (pid_t pid, size_t setsize, cpu_set_t *set) :récupérer l'affinité d'un processus et stocker le résultat danscpu_set_t.
Cependant, même si cpu_set_t représente un masque de bit, il ne faut jamais modifier cette structure manuellement mais plutôt utiliser des MACROS portables :
- CPU_ZERO() : initialiser la structure
cpu_set_tà zéro (aucun processeur). - CPU_SET() : ajouter un processeur à
cpu_set_t. - CPU_CLR() : retirer un CPU de la liste définit par
cpu_set_t. - CPU_ISSET() : vérifier l'existence d'un CPU dans
cpu_set_t.
Exemple : Illustration de l'affinité
Par défaut, un processus est autorisé à tourner sur tous les processeurs. Dans cet exemple, nous allons voir comment modifier ce comportement pour forcer l'exécution d'un programme sur les CPU0 et CPU1 :
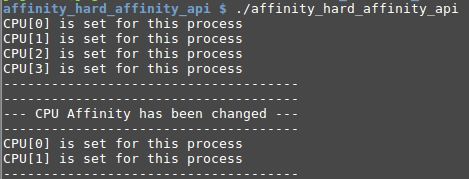
#define _GNU_SOURCE // getAffinityReturnValue() et set_process_affinity() // sont des extensions GNU. #include <stdio.h> #include <stdlib.h> #include <sched.h> cpu_set_t cpuSet; /* stocker l'affinité du processus. */ void get_process_affinity(){ int i = 0; // Remise à zéro avant lecture de l'affinité. CPU_ZERO(&cpuSet); // sched_getaffinity retourne l'affinité d'un processus // 0 : représente le processus en cours. if(sched_getaffinity(0, sizeof(cpu_set_t), &cpuSet) == -1){ perror("sched_getaffinity"); } /* Affichage de l'affinité. */ for(i = 0; i < CPU_SETSIZE; i++) { int isCPUSet = CPU_ISSET(i, &cpuSet); if(isCPUSet){ printf("CPU[%d] is set for this process\n", i); } } printf("-------------------------------------\n"); } void set_process_affinity(){ /* Remise à zéro de l'affinité. */ CPU_ZERO(&cpuSet); /* Autoriser l'affinité sur les CPU1 et CPU2. */ CPU_SET(0, &cpuSet); CPU_SET(1, &cpuSet); /* Interdire explicitement l'affinité sur les CPU3 et CPU4. * (CPU_ZERO() interdit tout les CPU). */ CPU_CLR(2, &cpuSet); /* Appliquer les nouvelles régles d'affinité. */ if( sched_setaffinity(0, sizeof(cpu_set_t), &cpuSet) == -1 ){ perror("sched_setaffinity"); } else { printf("-------------------------------------\n"); printf("--- CPU Affinity has been changed ---\n"); printf("-------------------------------------\n"); } } int main(int argc, char *argv[]){ /* Lecture de l'affinité initiale. */ get_process_affinity(); /* Forcer l'affinité sur le CPU0 et CPU1. */ set_process_affinity(); /* Relecture de l'affinité. */ get_process_affinity(); return EXIT_SUCCESS; }
L'exécution du programme est présenté sur l'image suivante :
Gestion des fréquences d'horloge et économie d'énergie
Souvent les systèmes embarqués doivent basculer vers l’état endormi pour réduire la consommation énergétique. Ceci est une autre contrainte pour le temps réel.
Une question cruciale se pose : comment répondre à une échéance rapidement après un réveil ou même existe-t-il un moyen de booster temporairement les performances d'un CPU ?
Pour répondre à cette question, nous devons aborder 2 notions différentes : le DVFS et le mode IDLE.
Horloge CPU et DVFS
La consommation CPU est souvent mesuré par la formule suivante :
P (CPU) = P (Statique) + P (dynamique)
où P (Statique) est causée par les courants de fuite des portes logiques et P (dynamique) par la commutation de ces dernières.
Ce qui nous intéresse le plus est le P (dynamique) calculé comme ceci :
P (dynamique) = C.f.V2
D'après cette formule, seules la fréquence et la tension peuvent être modifiées pour améliorer le rendement. En effet, C représente la capacité des portes logique et est donc fixe. Il faut retenir les 2 choses suivantes :
Augmenter la tension (de la façon décrite plus bas) pourra augmenter de manière considérable le rendement d'un CPU. Plusieurs constructeurs mettent à notre disposition les couples tension/fréquence optimum pour la tension donnée, appelés : points de performances de fonctionnement ou simplement OPP (Operating performance Points).
L’ensemble de ces points est géré par le DVFS (Dynamic Voltage and Frequency Scaling).
Sous Linux, Le DVFS est controllé par 2 sous-systèmes :
- CPUFreq : assure la transition entre les différents point OPP selon la politique du gouverneur.
- Les gouverneurs : décident du moment et de la manière de transiter d'un OPP à un autre.
En pratique, la configuration du DVFS est disponible dans le répertoire : /sys/devices/system/cpu/cpuX/cpufreq/ (la configuration peut être faite sur chaque CPU). Dans ce répertoire, on trouve les fichiers suivants :
- cpuinfo_transition_latency : latence de temps (en nanosecondes) pour basculer d'un OPP à un autre. La valeur est -1 si inconnu.
- scaling_available_frequencies : retourne la liste des OPP disponibles pour ce CPU.
- scaling_available_governors : affiche la liste des gouverneurs disponibles pour ce CPU. Voici la liste des plus connus (ils ne sont pas tous toujours disponibles sur tous les systèmes) :
- Performance : sélectionne la fréquence max possible.
- Powersave : sélectionne la fréquence min possible.
- Userspace : permet aux applications espace utilisateur, généralement un démon, d'assigner directement une fréquence.
- Ondemand : s'adapte automatiquement à la monté de charge, ce gouverneur a tendance à changer rapidement de OPP.
- Conservative : similaire à "Ondemand" mais la transition entre les OPP est plus homogène est moins brusque. Ce type de gouverneur est préconisé pour les systèmes sur batteries.
Exemple : Impact des gouverneurs
Il est possible d'illustrer la contribution que peut apporter le gouverneur au temps réel.
Pour çela nous allons :
- Fixer l'affinité du processus sur le processeur CPU2 .
- Comparer l'incrémentation d'un compteur (sur une période de 200 secondes) après applications des gouverneurs powersave et performance.
Voici un exemple d'implémentation :
int main(int argc, char *argv[]){ FILE *governorFile = NULL; cpu_set_t cpuSet; // Forcer l'affinité sur le CPU2 CPU_ZERO(&cpuSet); CPU_SET(2, &cpuSet); // Appliquer les nouvelles régles d'affinité. if( sched_setaffinity(0, sizeof(cpu_set_t), &cpuSet) == -1 ){ perror("sched_setaffinity"); return EXIT_FAILURE; } governorFile = fopen("/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor", "w+"); if(governorFile == NULL){ perror("ERROR "); return EXIT_FAILURE; } // Mettre le gouverneur du CPU2 en mode powersave. fprintf(governorFile, "powersave"); incrementCounter("Powersave governor "); // Mettre le gouverneur du CPU2 en mode performance. fprintf(governorFile, "performance"); incrementCounter("Performance governor"); fclose(governorFile); return EXIT_SUCCESS; }
N.B : la fonction incrementCounter() à été déja implémentée dans la partie temps réel.
Le résultat d'exécution montre clairement que le compteur s'incrémente plus rapidement avec le gouverneur "performance" (ce qui signifie une hausse des probabilités de respecter les échéances).

Il existe encore 3 fichiers indispensables pour la gestion du gouverneur :
- scaling_governor : retourne le gouverneur en cours d'utilisation (pour changer de gouverneur, il suffit d'écrire dans ce fichier).
- scaling_max_freq et scaling_min_freq : représente la fréquence min max respectivement associé au gouverneur en cours.
- scaling_setspeed : utilisé avec le gouverneur Userspace pour séléctionner la fréquence depuis l'espace utilisateur.
Le mode IDLE
Tout comme le mode DVFS, le mode IDLE est controlé par le driver CPUIdle. Cependant, il n'y a pas de possibilité de changer le gouverneur pendant le fonctionnement du système.
Toutes les informations sur le mode IDLE sont exposé sur : /sys/devices/system/cpu/cpuX/cpuidle/ (ou encore une fois, la configuration est propre pour chaque CPU). A l'intérieur de ce dossier on distingue l'ensemble des états IDLE supportés par le système nommés de state0 à stateN, où state0 représente l'etat idle le plus léger.
Chaque état contient les fichiers suivants :
- name : Nom de l'état IDLE.
- desc : Description de l'état.
- disable : Retourne le statut de l’état (activé ou non), une écriture de 1 sur ce fichier aura pour conséquence de désactiver cet état.
- latency : Latence (en ms) pour sortir de cet état IDLE et revenir au fonctionnement normal.
- time : Temps total d'exécution (en ms) dans cet état (mesuré par le kernel).
- usage : Nombre de fois où le Hardware à reçu une demande d'entrée dans cet état.
Le mode IDLE s'utilise de la même façon que les gouverneurs. Il suffit d'écrire dans le fichier du processeur en question.
L'avantage de choisir le mode léger (state0) est la possibilité du système de se réveiller et reprendre l'activité rapidement sans rater les échéances d'exécution (cependant, cela reste un mode qui consomme plus que les autres).
Conclusion
Dans cet article, nous avons découvert la notion du temps réel souple sous Linux et proposé des mécanismes pour avoir un système qui répond correctement à la quasi totalité des échéances.
Cependant, Linux reste un système trop complexe (avec plus de 20 millions lignes de codes) ce qui fait qu'il est impossible de tester tous les chemins et s'assurer que le code desservira toujours les tâches d'une manière déterministe.
Sans le patch temps-réel, Linux est donc limité au temps réel souple et non-garanti. Mais ceci est bien suffisant pour la plupart des cas d'utilisations.